对用户进行权限管理
在上一部分我们介绍了认证,认证指的是识别请求者身份的过程(比如使用密码、微信、手机号验证码等手段),在成功识别了用户的身份之后,我们接下来要做的就是管理、分配权限。
权限管理一般指根据系统设置的安全规则或者安全策略,用户可以访问而且只能访问自己被授权的资源,不多不少。
目前被大家广泛采用的两种权限模型为:基于角色的访问控制(RBAC)和基于属性的访问控制(ABAC),二者各有优劣:RBAC 模型构建起来更加简单,缺点在于无法做到对资源细粒度地授权(都是授权某一类资源而不是授权某一个具体的资源);ABAC 模型构建相对比较复杂,学习成本比较高,优点在于细粒度和根据上下文动态执行。
接下来,你可以了解如何为你的应用系统选择一种合适的权限模型。
选择合适的权限模型
目前被大家广泛采用的两种权限模型为:基于角色的访问控制(RBAC)和基于属性的访问控制(ABAC),二者各有优劣:RBAC 模型构建起来更加简单,缺点在于无法做到对资源细粒度地授权(都是授权某一类资源而不是授权某一个具体的资源);ABAC 模型构建相对比较复杂,学习成本比较高,优点在于细粒度和根据上下文动态执行。
什么是基于角色的访问控制(RBAC)
基于角色的访问控制(Role-based access control,简称 RBAC),指的是通过用户的角色(Role)授权其相关权限,这实现了更灵活的访问控制,相比直接授予用户权限,要更加简单、高效、可扩展。
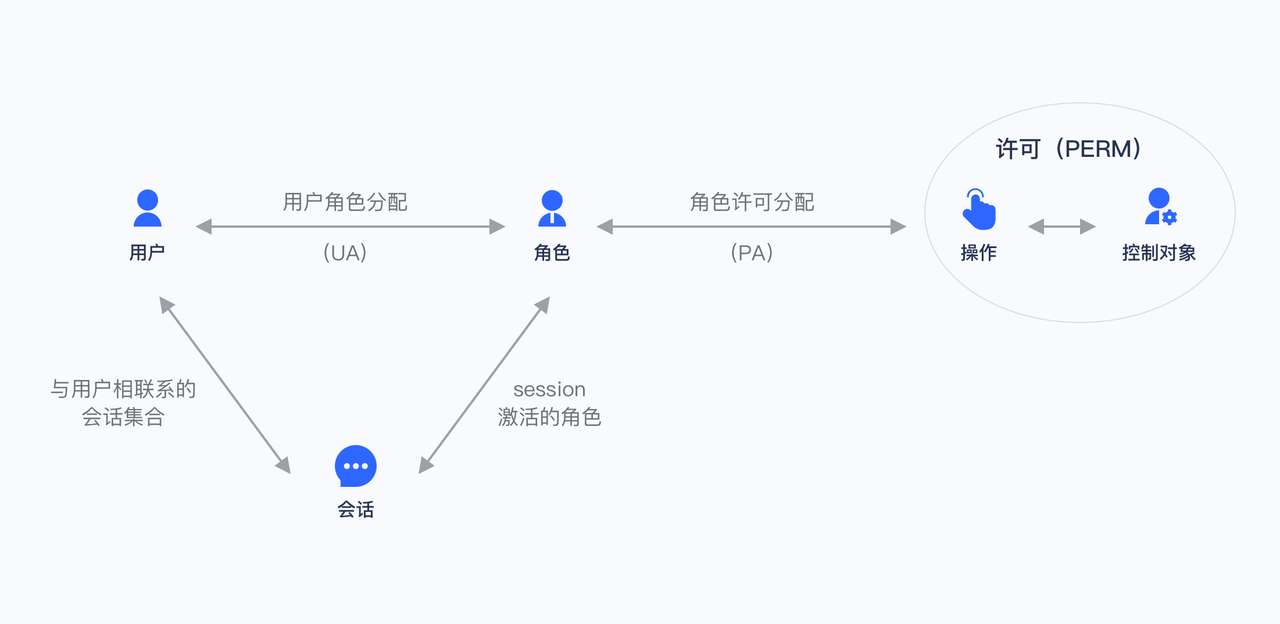
当使用 RBAC 时,通过分析系统用户的实际情况,基于共同的职责和需求,授予他们不同角色。你可以授予给用户一个或多个角色,每个角色具有一个或多个权限,这种 用户-角色、角色-权限 间的关系,让我们可以不用再单独管理单个用户,用户从授予的角色里面继承所需的权限。
以一个简单的场景(Gitlab 的权限系统)为例,用户系统中有 Admin、Maintainer、Operator 三种角色,这三种角色分别具备不同的权限,比如只有 Admin 具备创建代码仓库、删除代码仓库的权限,其他的角色都不具备。
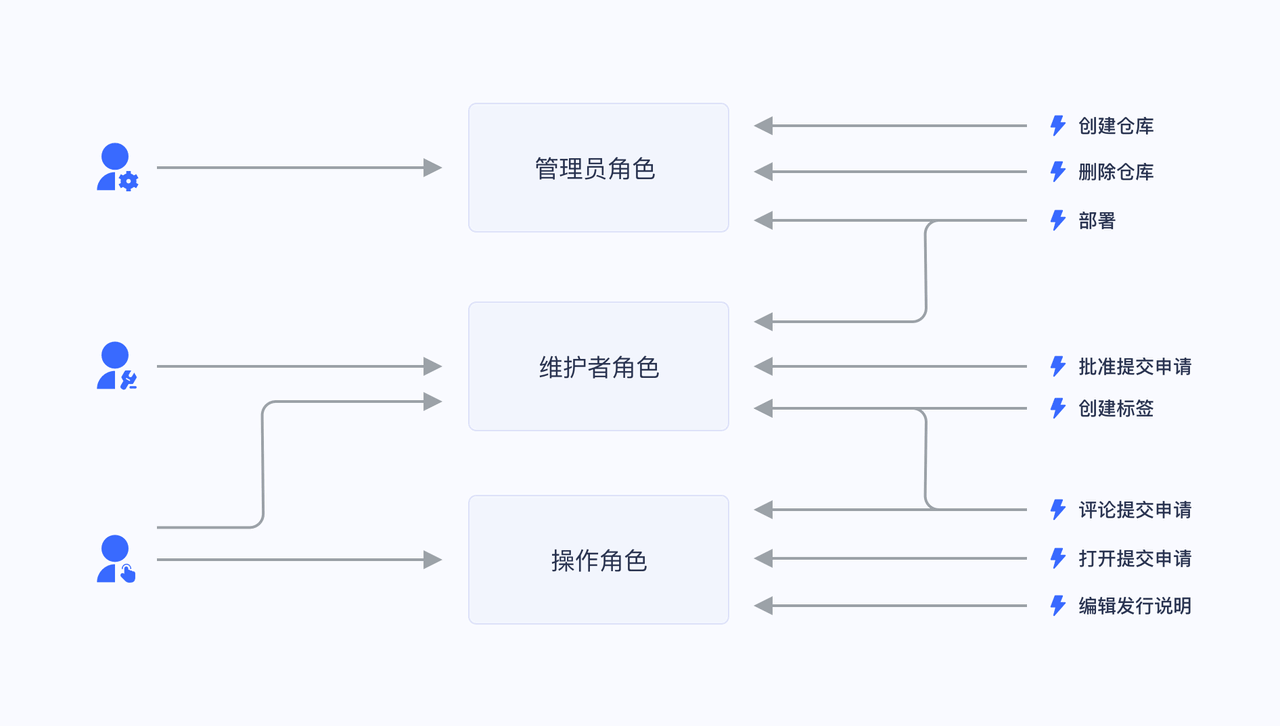
我们授予某个用户「Admin」这个角色,他就具备了「创建代码仓库」和「删除代码仓库」这两个权限。
不直接给用户授权策略,是为了之后的扩展性考虑。比如存在多个用户拥有相同的权限,在分配的时候就要分别为这几个用户指定相同的权限,修改时也要为这几个用户的权限进行一一修改。有了角色后,我们只需要为该角色制定好权限后,给不同的用户分配不同的角色,后续只需要修改角色的权限,就能自动修改角色内所有用户的权限。
什么是基于属性的访问控制(ABAC)
基于属性的访问控制(Attribute-Based Access Control,简称 ABAC)是一种非常灵活的授权模型,不同于 RBAC,ABAC 则是通过各种属性来动态判断一个操作是否可以被允许。
ABAC 的主要组成部分
在 ABAC 中,一个操作是否被允许是基于对象、资源、操作和环境信息共同动态计算决定的。
- 对象:对象是当前请求访问资源的用户。用户的属性包括ID,个人资源,角色,部门和组织成员身份等;
- 资源:资源是当前访问用户要访问的资产或对象(例如文件,数据,服务器,甚至API)。资源属性包含文件的创建日期,文件所有者,文件名和类型以及数据敏感性等等;
- 操作:操作是用户试图对资源进行的操作。常见的操作包括“读取”,“写入”,“编辑”,“复制”和“删除”;
- 环境:环境是每个访问请求的上下文。环境属性包含访问尝试的时间和位置,对象的设备,通信协议和加密强度等。
ABAC 如何使用属性动态计算出决策结果
在 ABAC 的决策语句的执行过程中,决策引擎会根据定义好的决策语句,结合对象、资源、操作、环境等因素动态计算出决策结果。、
每当发生访问请求时,ABAC 决策系统都会分析属性值是否与已建立的策略匹配。如果有匹配的策略,访问请求就会被通过。
例如,策略「当一个文档的所属部门跟用户的部门相同时,用户可以访问这个文档」会被以下属性匹配:
- 对象(用户)的部门 = 资源的所属部门;
- 资源 = “文档”;
- 操作 = “访问”;
策略「早上九点前禁止 A 部门的人访问B系统;」会被以下属性匹配:
- 对象的部门 = A 部门;
- 资源 = “B 系统”;
- 操作 = “访问”;
- 环境 = “时间是早上 9 点”。
ABAC 应用场景
在 ABAC 权限模型下,你可以轻松地实现以下权限控制逻辑:
- 授权 A 具体某部门的编辑权限;
- 当一个文档的所属部门跟用户的部门相同时,用户可以访问这个文档;
- 当用户是一个文档的拥有者并且文档的状态是草稿,用户可以编辑这个文档;
- 早上九点前禁止 A 部门的人访问 B 系统;
- 在除了上海以外的地方禁止以管理员身份访问 A 系统;
上述的逻辑中有几个共同点:
- 具体到某一个而不是某一类资源;
- 具体到某一个操作;
- 能通过请求的上下文(如时间、地理位置、资源 Tag)动态执行策略;
如果浓缩到一句话,你可以 细粒度地授权在何种情况下对某个资源具备某个特定的权限。
GenAuth 的权限模型
在 GenAuth 中有几个概念:
- 用户:你的终端用户;
- 角色:角色是一个逻辑集合,你可以授权一个角色某些操作权限,然后将角色授予给用户,该用户将会继承这个角色中的所有权限;
- 资源:你可以把你应用系统中的实体对象定义为资源,比如订单、商品、文档、书籍等等,每种资源都可以定义多个操作,比如文档有阅读、编辑、删除操作;
- 授权:把某类(个)资源的某些(个)操作授权给角色或者用户。
在 GenAuth 的权限系统中,我们通过用户、角色这两种对象实现了 RBAC 模型的角色权限继承,在此之上,我们还能围绕属性进行动态地、细粒度地授权,从而实现了 ABAC 权限模型。同时,我们为了满足大型系统中复杂组织架构的设计需求,将资源、角色、权限授权统一组合到一个权限分组中,方便开发者进行管理。
我该如何选择使用哪种权限模型
在这里,组织的规模是至关重要的因素。由于 ABAC 最初的设计和实施困难,对于小型企业而言,考虑起来可能太复杂了。
对于中小型企业,RBAC 是 ABAC 的简单替代方案。每个用户都有一个唯一的角色,并具有相应的权限和限制。当用户转移到新角色时,其权限将更改为新职位的权限。这意味着,在明确定义角色的层次结构中,可以轻松管理少量内部和外部用户。
但是,当必须手动建立新角色时,对于大型组织而言,效率不高。一旦定义了属性和规则,当用户和利益相关者众多时,ABAC 的策略就更容易应用,同时还降低了安全风险。
简而言之,如果满足以下条件,请选择 ABAC:
- 你在一个拥有许多用户的大型组织中;
- 你需要深入的特定访问控制功能;
- 你有时间投资远距离的模型;
- 你需要确保隐私和安全合规;
但是,如果满足以下条件,请考虑 RBAC:
- 你所在的是中小型企业;
- 你的访问控制策略广泛;
- 你的外部用户很少,并且你的组织角色得到了明确定义;
接下来
接下来,你可以了解如何集成 RBAC 权限模型到你的应用系统或者集成 ABAC 权限模型到你的应用系统。
集成 RBAC 权限模型到你的应用系统
前面我们介绍了什么是基于角色的访问控制(RBAC),接下来这篇文章介绍如何基于 GenAuth 快速将 RBAC 权限模型集成到你的系统中。
首先了解一下 GenAuth 中的几个核心概念:
- 用户:你的终端用户;
- 角色:角色是一个逻辑集合,你可以授权一个角色某些操作权限,然后将角色授予给用户,该用户将会继承这个角色中的所有权限;
- 资源:你可以把你应用系统中的实体对象定义为资源,比如订单、商品、文档、书籍等等,每种资源都可以定义多个操作,比如文档有阅读、编辑、删除操作;
- 授权:把某类(个)资源的某些(个)操作授权给角色或者用户。
通过用户、角色、资源、授权的组合,就可以轻松直观地实现灵活、细粒度的权限模型。
创建角色
你可以使用 GenAuth 控制台创建角色:在权限管理 - 角色管理中,点击添加角色按钮:
- 角色 code: 该角色的唯一标志符,权限分组内具有唯一性,只允许包含英文字母、数字、下划线 _、横线 -,这里我们填
admin。 - 角色描述:该角色的描述信息,这里我们填
管理员。
创建好三个角色:
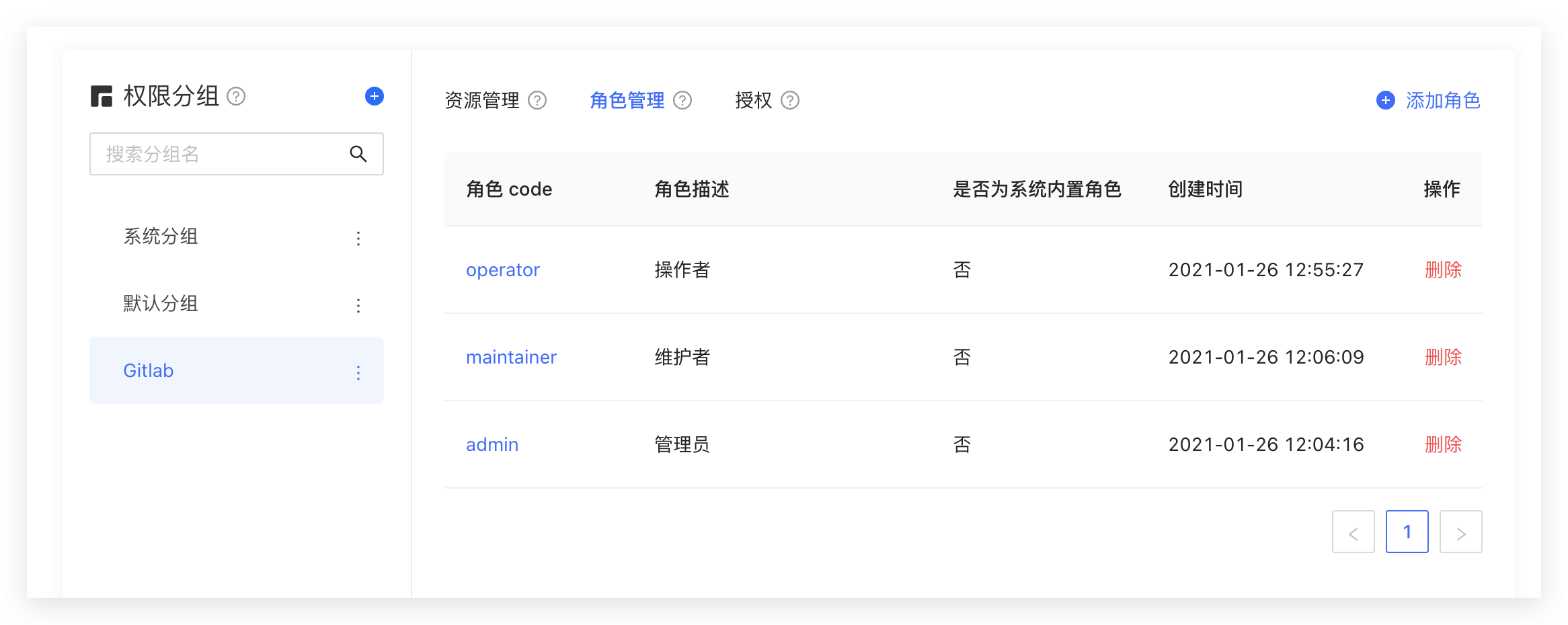
你也可以使用 API & SDK 创建角色,详情请见角色 Management SDK。
授权用户角色
在角色详情页面,你可以将此角色授权给用户。你可以通过用户名、手机号、邮箱、昵称搜索用户:

选择用户之后点击确认,你可以查看被授权此角色的用户列表。
你也可以使用 API & SDK 给用户授予角色,详情请见角色 Management SDK。
在后端通过用户角色控制权限
当用户成功认证、获取到 Token 之后,你可以解析到当前用户的 ID,接下来你可以使用我们提供的 API & SDK 在后端获取该用户被授予的角色,这里以 Node.js 为例:
这里以 Node SDK 为例,我们同时还支持 Python、Java、C#、PHP 等语言的 SDK,详情请点击此。
首先获取用户的被授予的所有角色列表:
import { ManagementClient } from 'authing-js-sdk'
const managementClient = new ManagementClient({
userPoolId: 'YOUR_USERPOOL_ID',
secret: 'YOUR_USERPOOL_SECRET',
})
const { totalCount, list } = await managementClient.users.listRoles('USER_ID')得到用户的所有角色之后,我们可以判断该用户是否具备 devops 这个角色:
if (!list.map((role) => role.code).includes('devops')) {
throw new Error('无权限操作!')
}创建资源
上一步我们通过用户是否具备某个角色来控制权限,这种权限控制还是比较粗粒度的,因为只判断了用户是否具备某个角色,而没有判断其是否具备某个特定的权限。GenAuth 在基于角色的访问控制模型(RBAC)的基础上,还能够围绕资源进行更细粒度的授权。
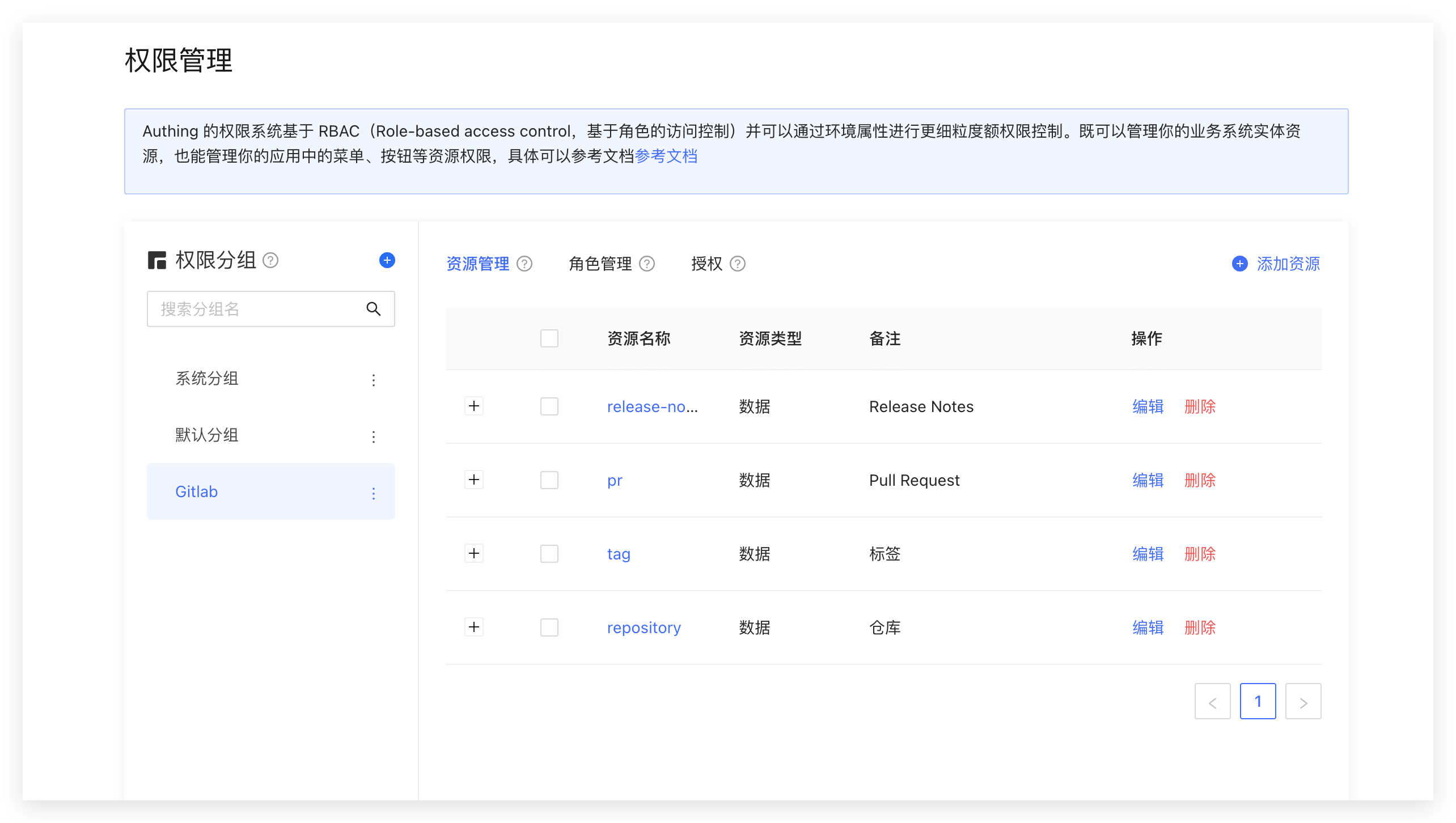
你可以把系统的一些对象抽象为资源,在这些资源上可以定义了一些操作。比如在本文的场景中,Repository、Tag、PR、Release Notes 都是资源,且这些资源都有对应的操作:
- Repository:创建、删除等。
- PR:开启、评论、合并等。
- Tag:创建、删除等。
- Release Notes:创建、阅读、编辑、删除等。
我们在 GenAuth 中创建这些资源:
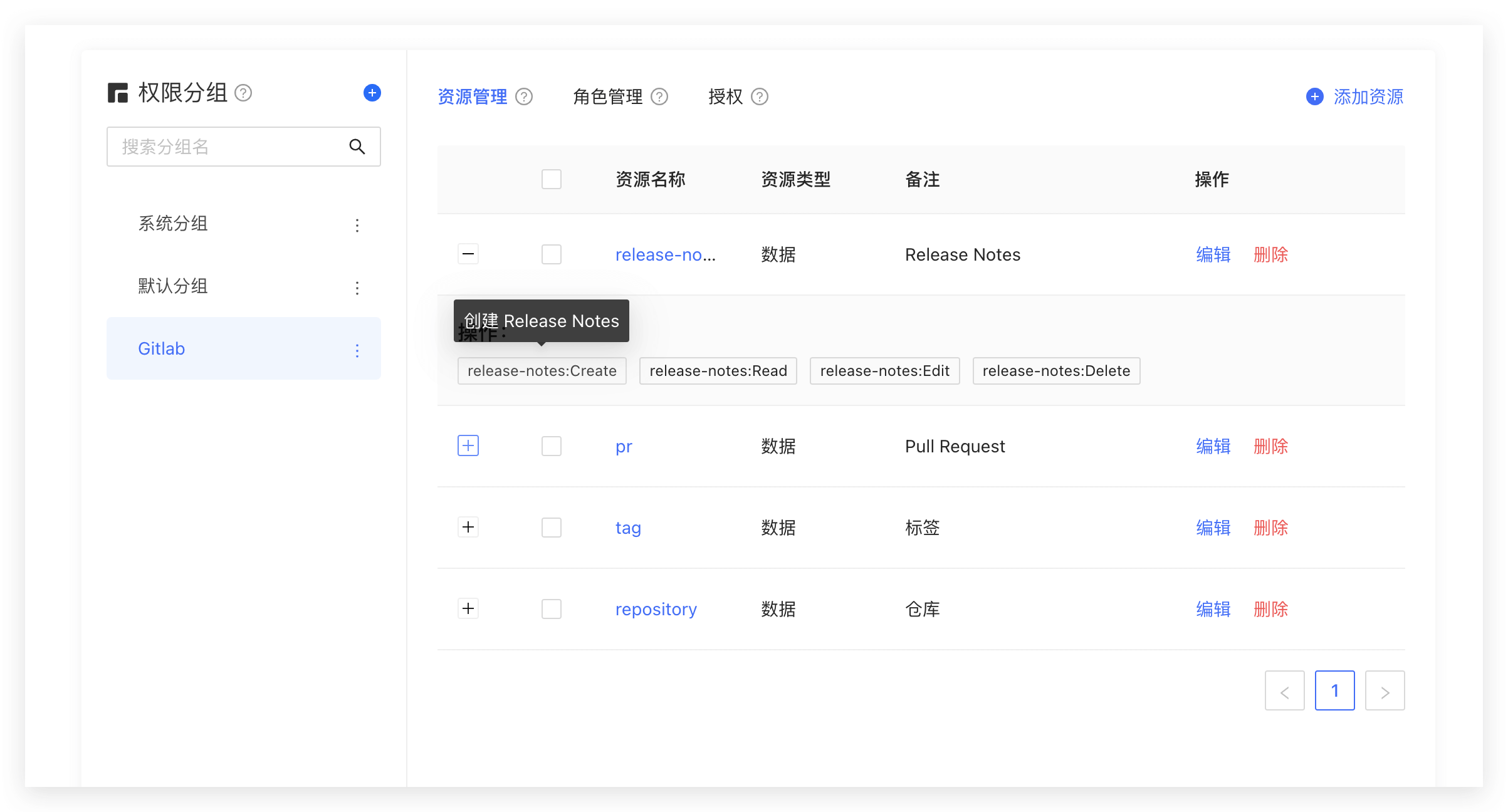
授权角色操作资源的权限
而且 GenAuth 还同时支持给用户、角色授权,如果用户在某个角色中,他也将继承这个角色被授权的权限。所以 GenAuth 既能够实现标准的 RBAC 权限模型,也能在这基础上进行更细粒度、更动态的权限控制。
比如下面这个例子中,我们给 admin 这个角色授权了 repository 资源的 Create 和 Delete 权限:
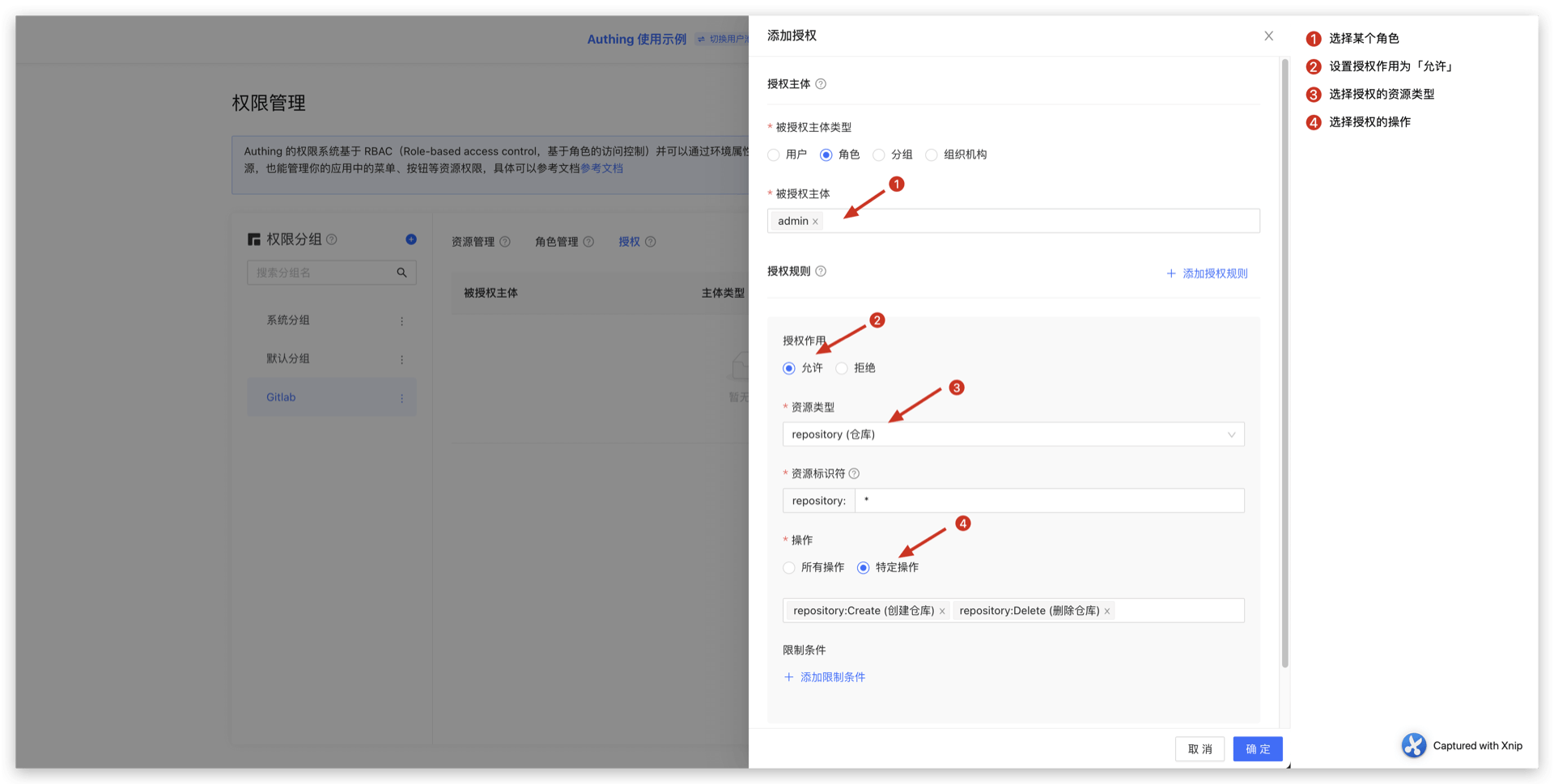
在后端判断用户是否具备权限
在上一步我们通过资源授权,做到了授权给某个用户(角色)对某个特定资源的特定操作权限,我们在后端进行接口鉴权的时候,就可以做更细粒度的判断了:
这里以 Node SDK 为例,我们同时还支持 Python、Java、C#、PHP 等语言的 SDK,详情请点击此。
调用 managementClient.acl.isAllowed 方法,参数分别为:
- userId: 用户 ID,用户可以被直接授权特定资源的操作,也可以继承角色被授权的权限。
- resource: 资源标志符,如
repository:123表示 ID 为 123 的代码仓库,repository:*表示代码仓库这一类资源。 - action: 特定操作,如
repository:Delete表示删除代码仓库这个操作。 - options: 其他选项,可选
- options.namespace,资源所属权限分组 code
import { ManagementClient } from 'authing-js-sdk'
const managementClient = new ManagementClient({
userPoolId: 'YOUR_USERPOOL_ID',
secret: 'YOUR_USERPOOL_SECRET',
})
const { totalCount, list } = await managementClient.acl.isAllowed(
'USER_ID',
'repository:123',
'repository:Delete'
)GenAuth 策略引擎会根据你配置的权限策略,动态执行策略,最后返回 true 或者 false,你只需要根据返回值就能判断用户是否具备操作权限。
接下来
你可以了解如何基于 ABAC 权限模型对用户进行授权。
集成 ABAC 权限模型到你的应用系统
前面我们介绍了什么是基于属性的访问控制(ABAC),接下来这篇文章介绍如何基于 GenAuth 快速将 ABAC 权限模型集成到你的系统中。在上一讲中我们介绍了如何将 RBAC 权限模型的集成方法,相信你也意识到了,RBAC 权限模型是静态的,也就是没有环境、对象属性等动态属性参与,所以很难实现类似于以下场景的访问控制:
- 当一个文档的所属部门跟用户的部门相同时,用户可以访问这个文档;
- 当用户是一个文档的拥有者并且文档的状态是草稿,用户可以编辑这个文档;
- 早上九点前禁止 A 部门的人访问 B 系统;
- 在除了上海以外的地方禁止以管理员身份访问 A 系统;
ABAC 的主要组成部分
在 ABAC 中,一个操作是否被允许是基于对象、资源、操作和环境信息共同动态计算决定的。
- 对象:对象是当前请求访问资源的用户。用户的属性包括ID,个人资源,角色,部门和组织成员身份等;
- 资源:资源是当前访问用户要访问的资产或对象(例如文件,数据,服务器,甚至API)。资源属性包含文件的创建日期,文件所有者,文件名和类型以及数据敏感性等等;
- 操作:操作是用户试图对资源进行的操作。常见的操作包括“读取”,“写入”,“编辑”,“复制”和“删除”;
- 环境:环境是每个访问请求的上下文。环境属性包含访问尝试的时间和位置,对象的设备,通信协议和加密强度等。
ABAC 如何使用属性动态计算出决策结果
在 ABAC 的决策语句的执行过程中,决策引擎会根据定义好的决策语句,结合对象、资源、操作、环境等因素动态计算出决策结果。、
每当发生访问请求时,ABAC 决策系统都会分析属性值是否与已建立的策略匹配。如果有匹配的策略,访问请求就会被通过。
例如,策略「当一个文档的所属部门跟用户的部门相同时,用户可以访问这个文档」会被以下属性匹配:
- 对象(用户)的部门 = 资源的所属部门;
- 资源 = “文档”;
- 操作 = “访问”;
策略「早上九点前禁止 A 部门的人访问B系统;」会被以下属性匹配:
- 对象的部门 = A 部门;
- 资源 = “B 系统”;
- 操作 = “访问”;
- 环境 = “时间是早上 9 点”。
在 GenAuth 中授权资源的时候指定限制条件
我们在授权资源的时候,可以指定限制条件。例如在下面的例子中,我们添加了一个限制条件:要求当前请求的用户经过了 MFA 认证。

除了 MFA 认证这个属性外,你还可以在 GenAuth 的策略引擎上下文中获取以下属性:
- 用户对象属性,如性别、组织机构、分组、角色、邮箱是否验证、手机号是否验证、自定义数据、是否经过了 MFA 认证、用户上次 MFA 认证时间等;
- 环境属性:客户端 IP、客户端 UA、客户端浏览器、请求来源国家、请求来源省份、请求来源城市等;
- 资源属性:资源创建时间、资源拥有者、资源标签等;
你可以根据这些属性组成灵活的策略授权语句。
使用权限分组管理权限资源
权限分组可以理解为权限的命名空间,不同权限分组中的角色和资源相互独立,即使同名也不会冲突。

创建权限分组
在权限管理的权限分组菜单中点击添加按钮: 
在弹窗中填入分组名和分组标识符,标识符用于后期鉴权时作为唯一标识识别权限组。

在创建的权限分组中就可以使用前面介绍的 ABAC 或 RBAC 权限模型对权限资源独立管理了。
如何使用权限分组判断权限
import { ManagementClient } from 'authing-js-sdk'
const managementClient = new ManagementClient({
userPoolId: 'YOUR_USERPOOL_ID',
secret: 'YOUR_USERPOOL_SECRET',
})
const { totalCount, list } = await managementClient.acl.isAllowed(
'USER_ID',
'资源',
'操作',
'权限分组标识符'
)权限分组与应用的关系
在每个应用创建时,GenAuth 都会为你创建一个权限分组。自动创建的权限分组名为应用名,标识符为应用 ID,且不可修改。GenAuth 也会为每个用户池创建一个默认权限分组,当你的权限资源比较简单,不需要在应用层面隔离管理时,可以直接使用默认权限分组。当你的某个应用比较复杂,存在冲突的角色或资源时,就可以通过自己手动创建权限分组来隔离管理权限资源。
管理资源权限
作为管理员,你可以在控制台管理和分配资源的权限。在实践权限管理和授权之前,需要先了解几个概念。
- 应用:作为管理员,你能够创建应用,应用就是你正在开发的应用项目在 GenAuth 的一个定义,例如正在实际开发一个「网络笔记」应用,你就应该在 GenAuth 创建一个名为「网络笔记」的应用。
- 资源:之后你可以在 GenAuth 中定义一些资源,例如「网络笔记」应用中的资源可能有笔记本、笔记内容、作者等等。
- 用户:你也可以直接将权限指派到用户,你也可以将你的用户划分成不同的分组、角色、组织机构部门,这样在以后分配权限的时候方便管理。
- 角色:角色是一组用户的集合,角色中的用户会自动继承该角色被授权的权限。
下面我们创建应用、创建资源、创建用户,然后定义资源与用户的授权关系。
创建应用
请查看创建应用文档。
创建资源
在应用下访问授权的资源卡片,点击右边的添加按钮。
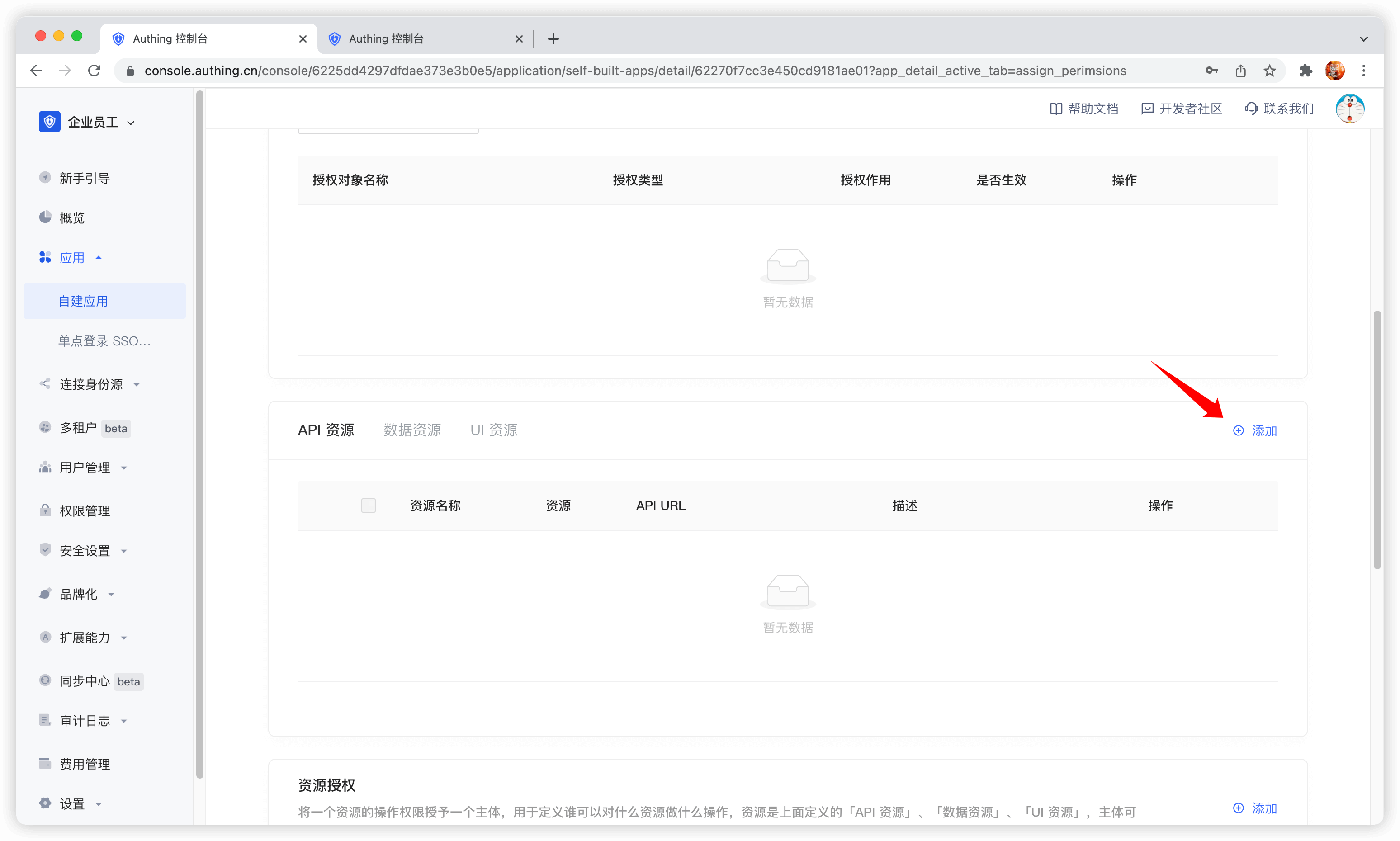
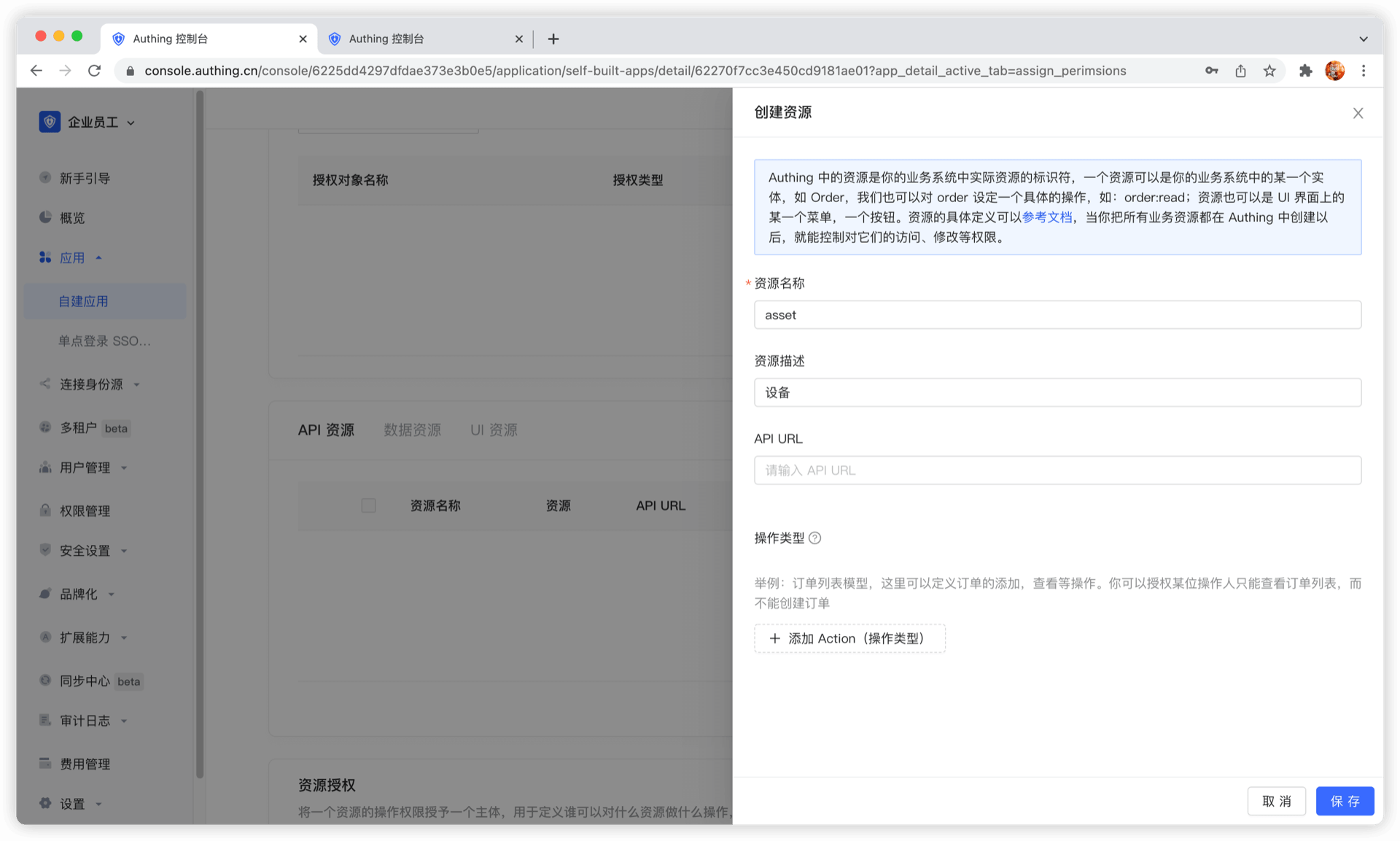
然后填写一个资源名称,建议填写语义化的资源名称,便于后续管理。在操作类型中可以定义资源操作,这里定义了读取和写入操作。最后点击保存,一个资源就创建好了。
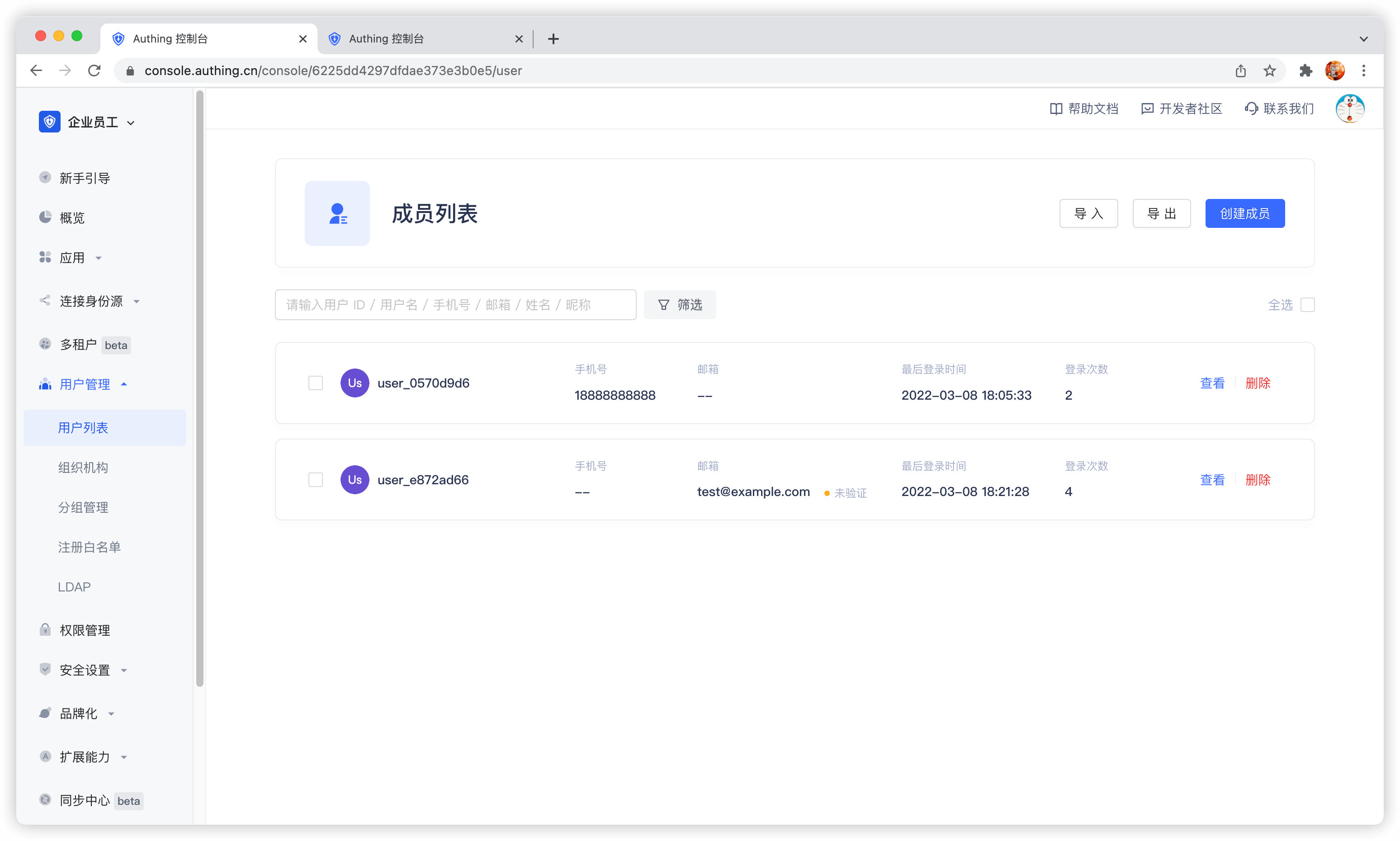
创建用户
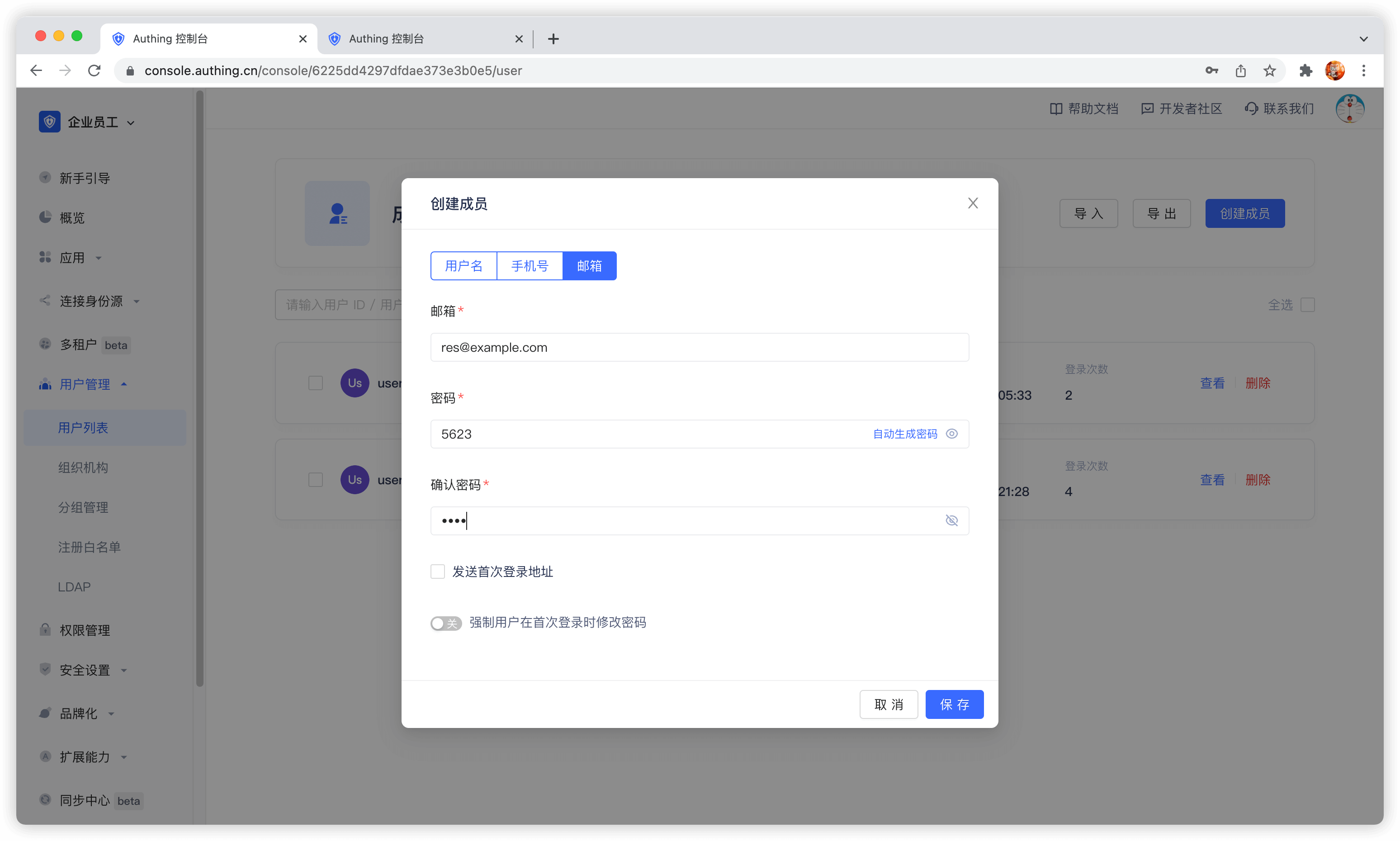
在用户列表,点击新建,创建一个用户。
创建角色
在应用详情 - 访问授权 菜单的 角色管理卡片中,点击右边的添加按钮:
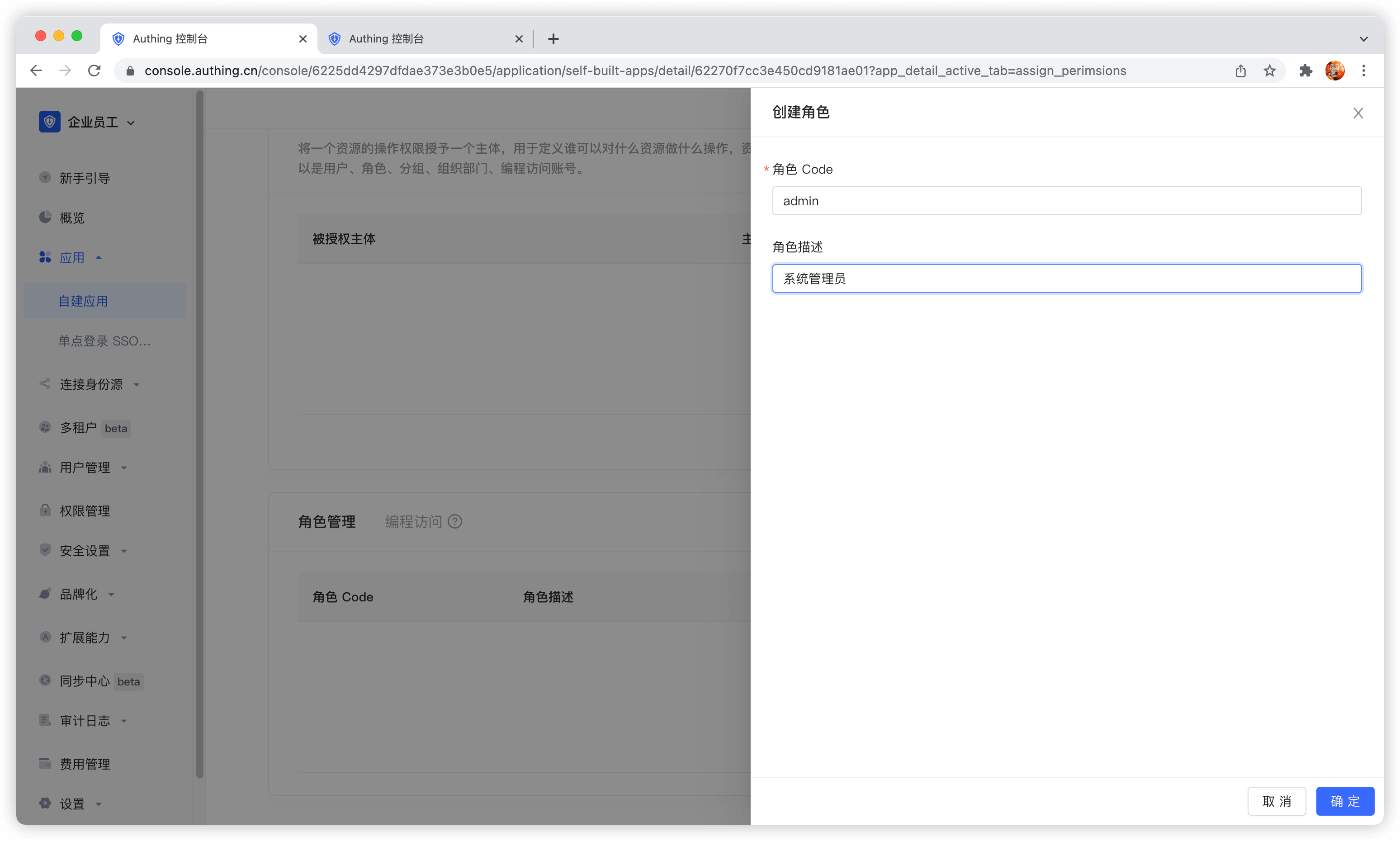
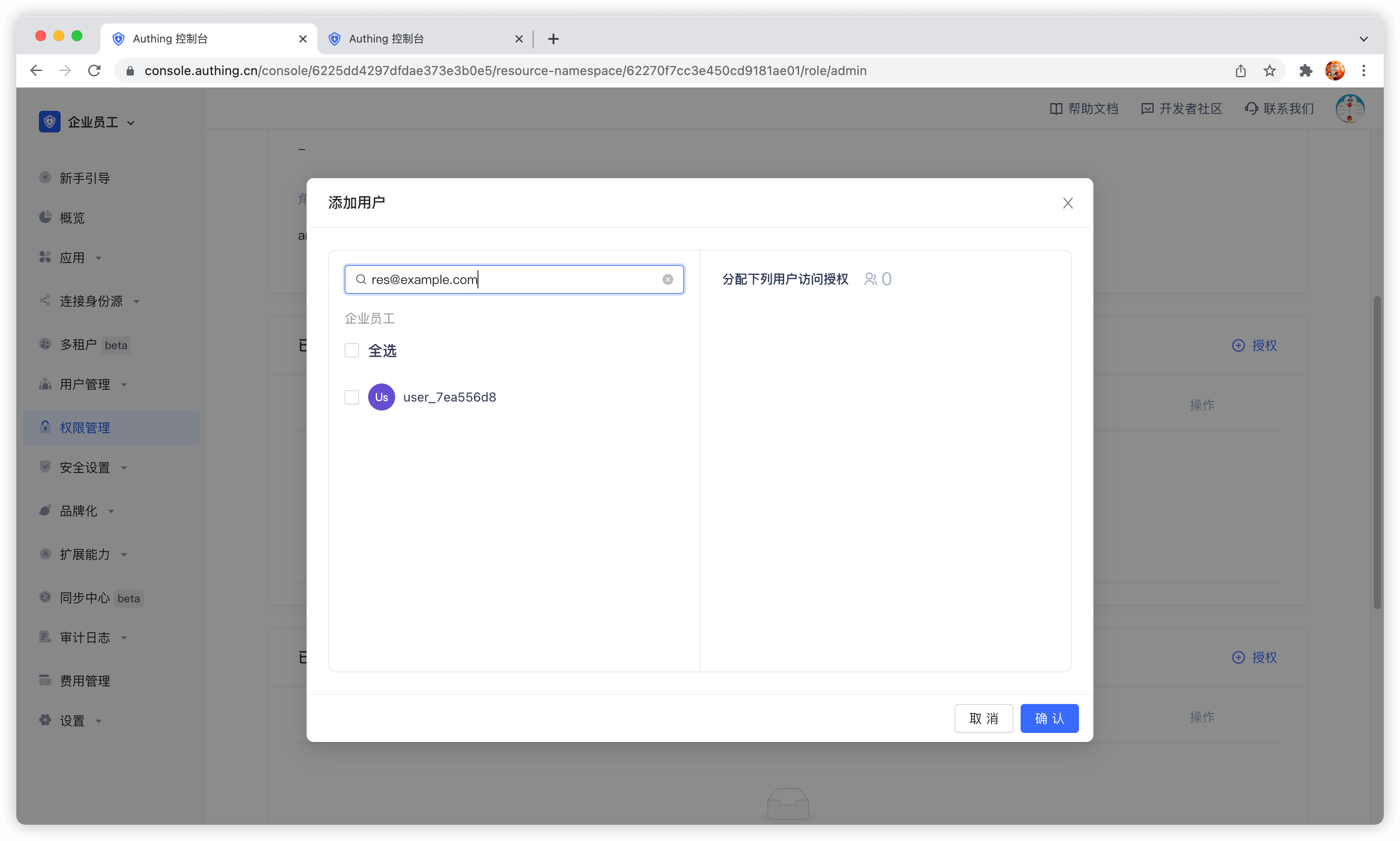
创建完角色之后,你可以往这个角色中添加用户:
你可以通过用户名、邮箱、昵称搜索用户。
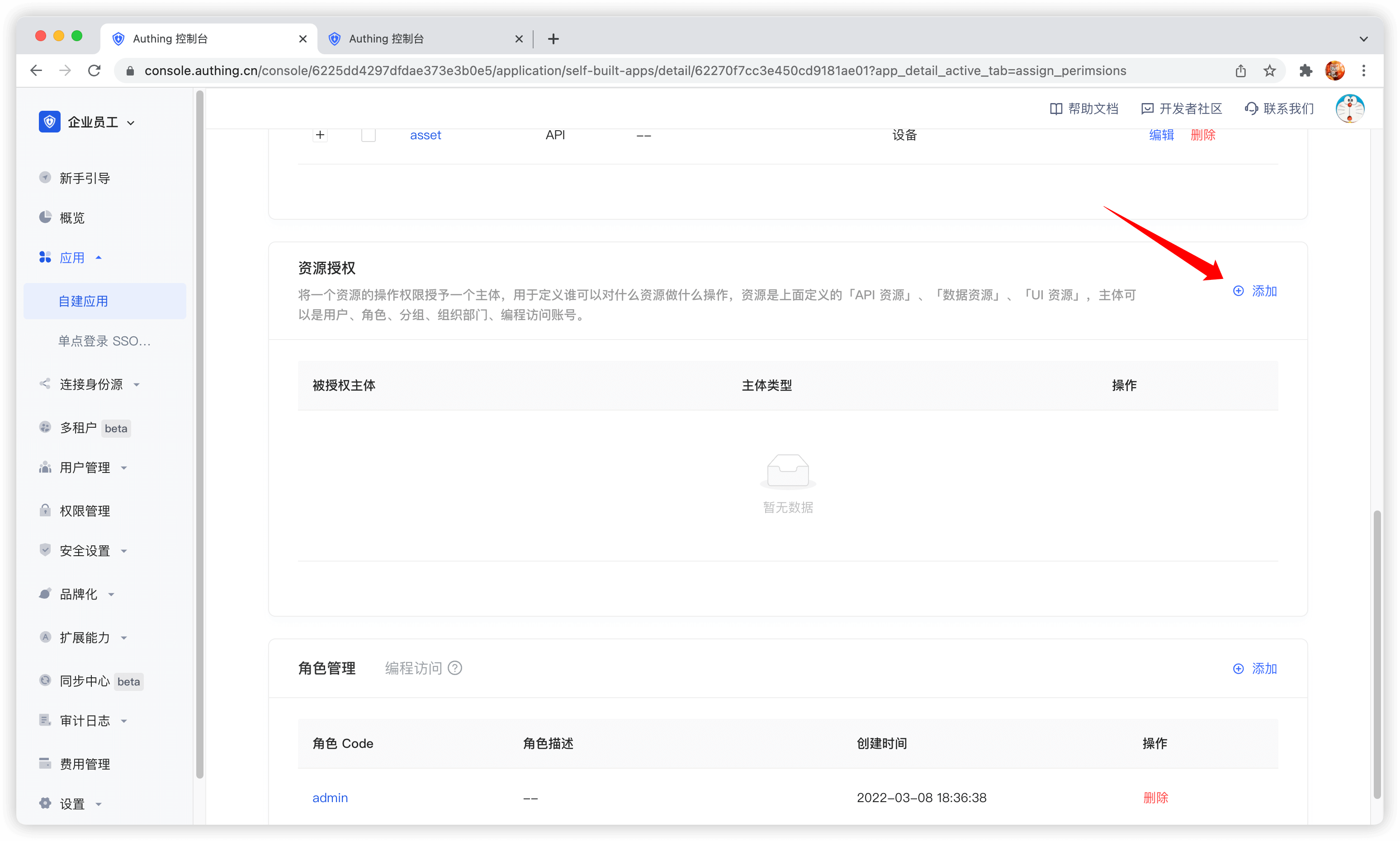
管理权限
现在你有了资源和人,接下来你要定义「谁」能够对什么「资源」做什么「操作」。 在应用的资源授权卡片中,点击右侧的添加按钮。
被授权主体可以选择用户,这里我们选择刚刚创建的用户,在下方的资源类型中选择我们刚刚创建的设备资源。 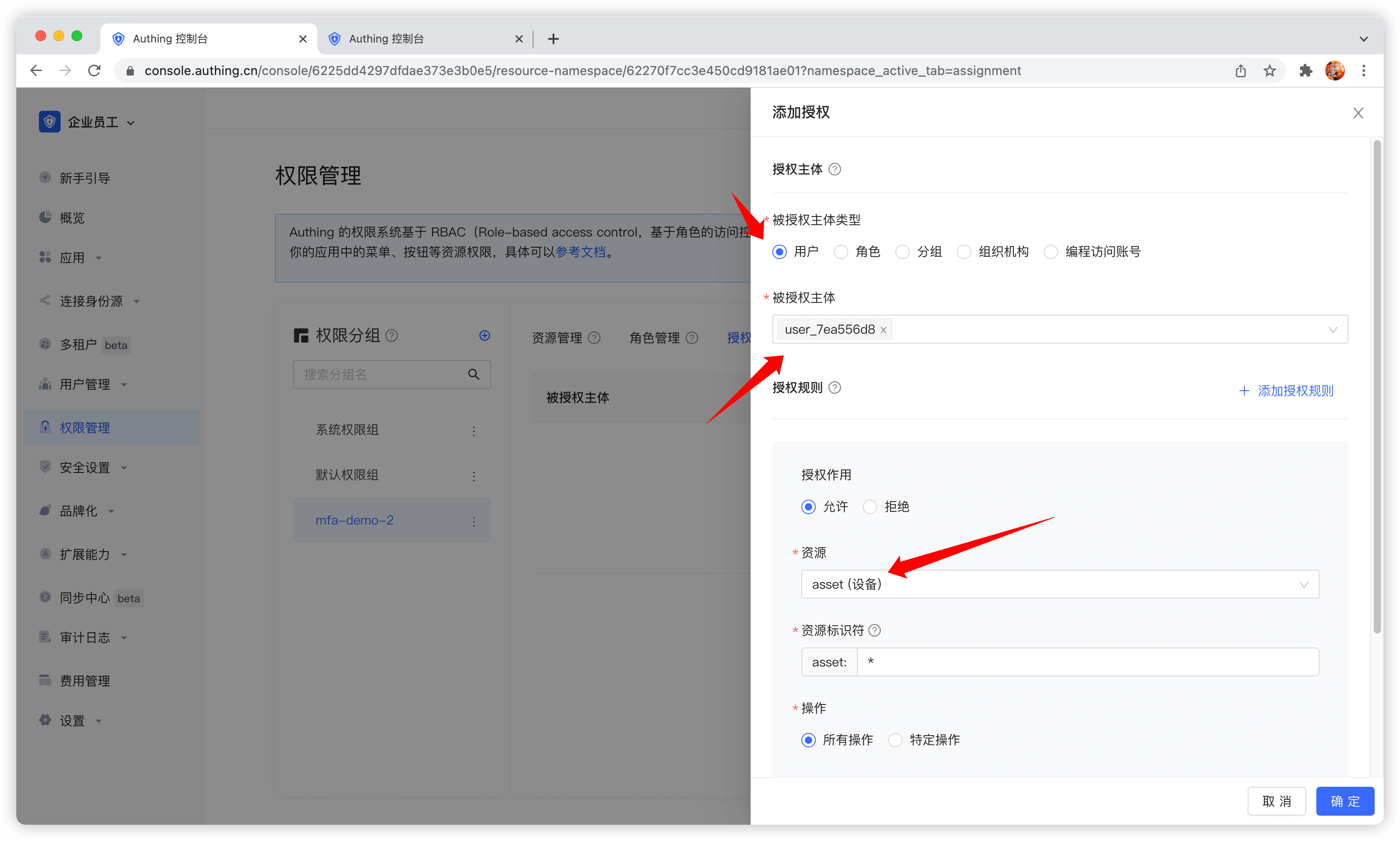
同时被授权主体也可以选择角色,这样角色中的所有用户都会自动继承该角色被授权的权限。
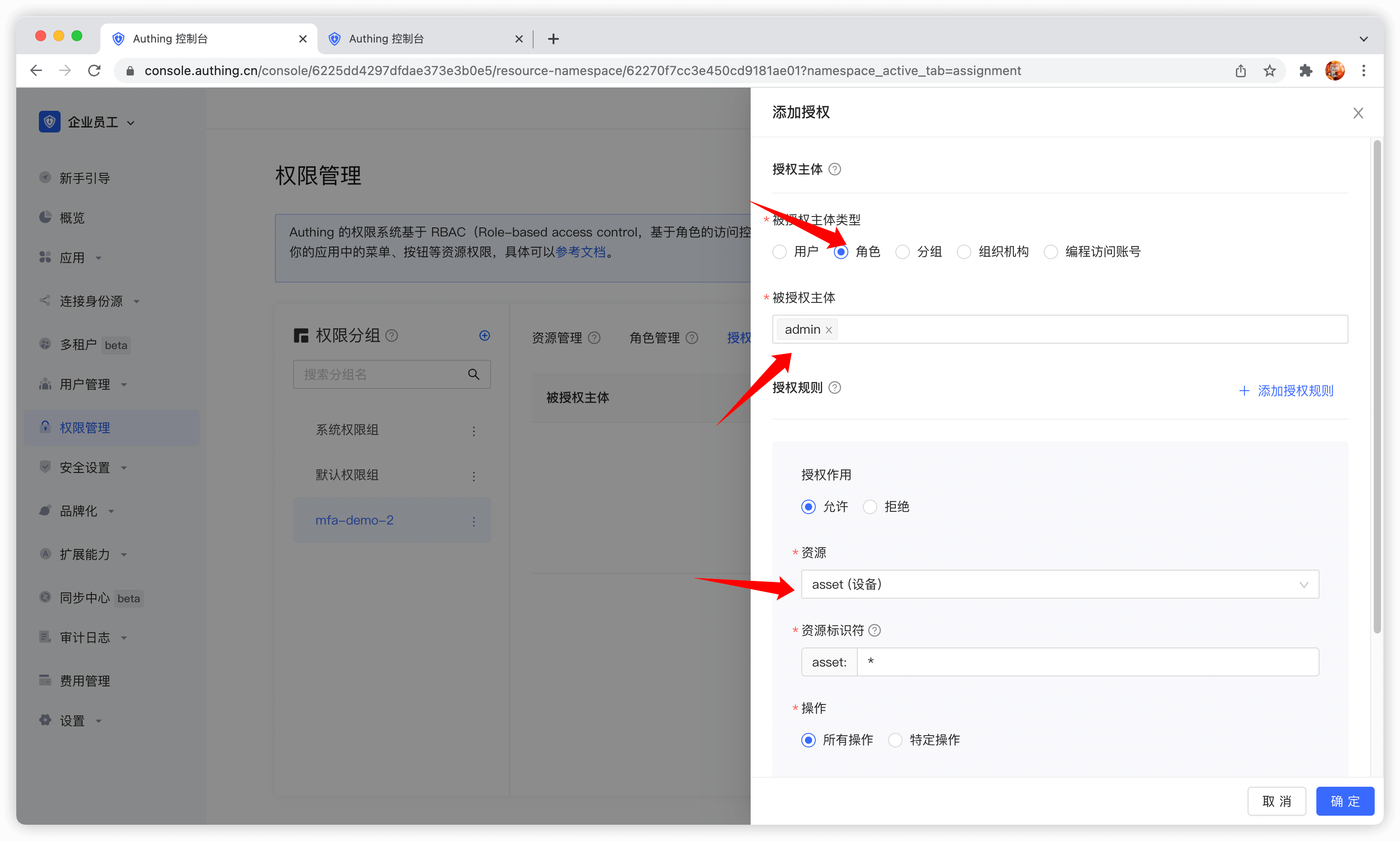
然后资源标识符填写 *,代表授权所有设备资源,操作选择特定操作,选择我们刚刚定义的资源操作中的读取设备列表操作,最后点击确定。
如果填写一个具体的标识符,例如 42,则表示将编号为 42 的设备资源授权给主体。主体只具备 asset:42 这个资源的权限,授权时最多只能授权出 asset:42 资源的相关权限。
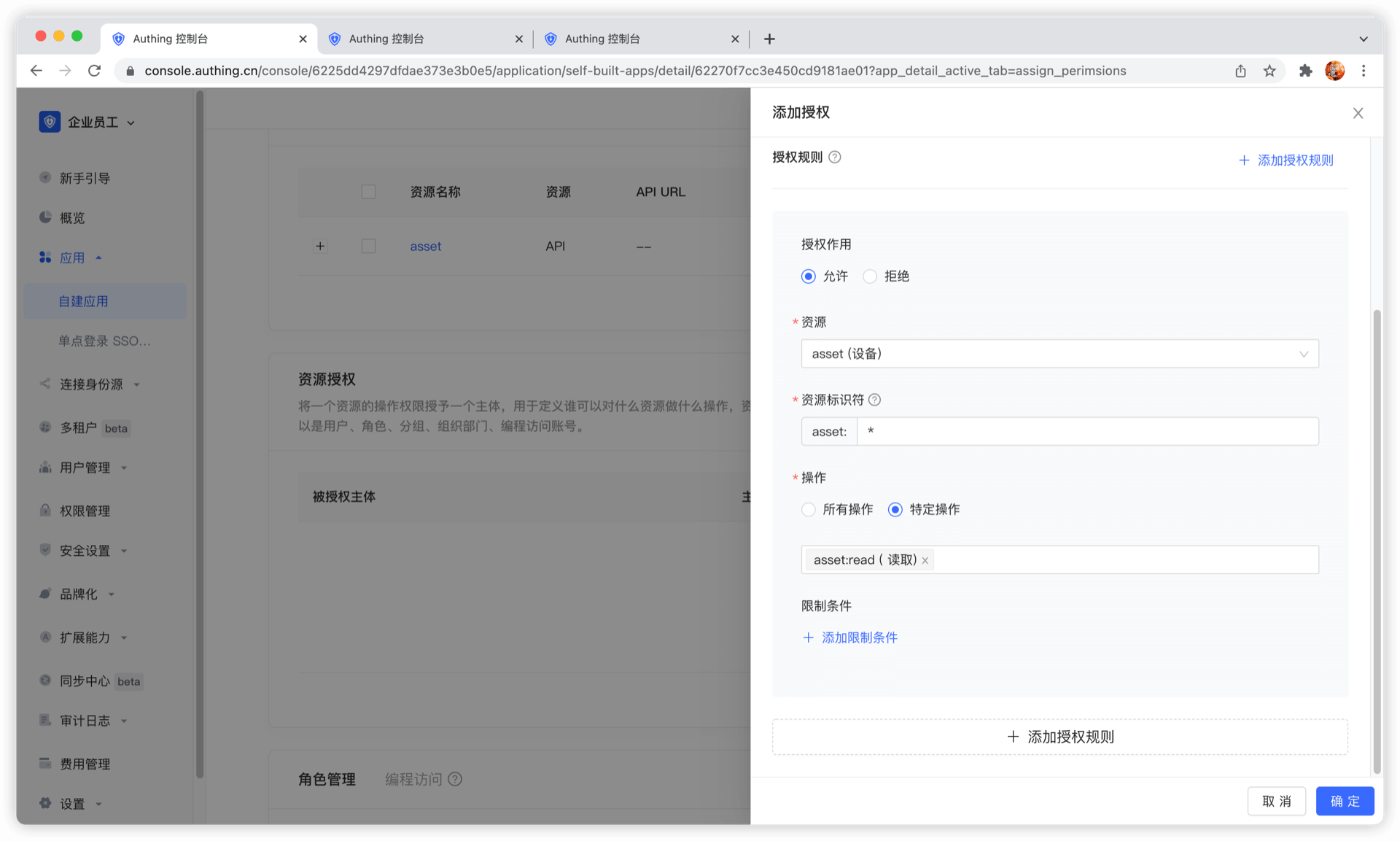
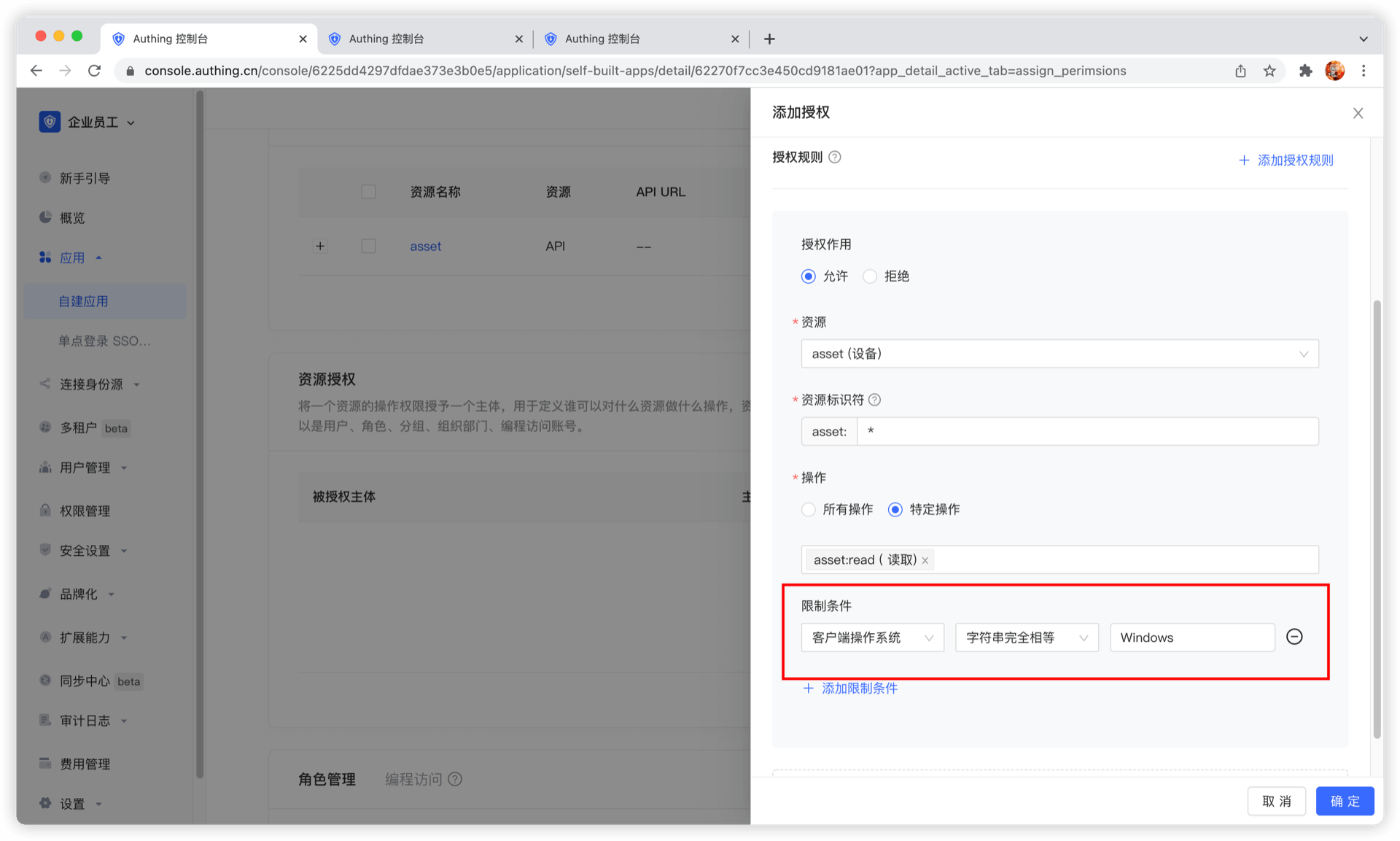
我们还可以为授权规则添加限制条件,例如该规则只针对 Windows 用户有效。如果从 Linux 机器上发起授权,GenAuth 会认为用户无权限,无法完成设备资源的授权。
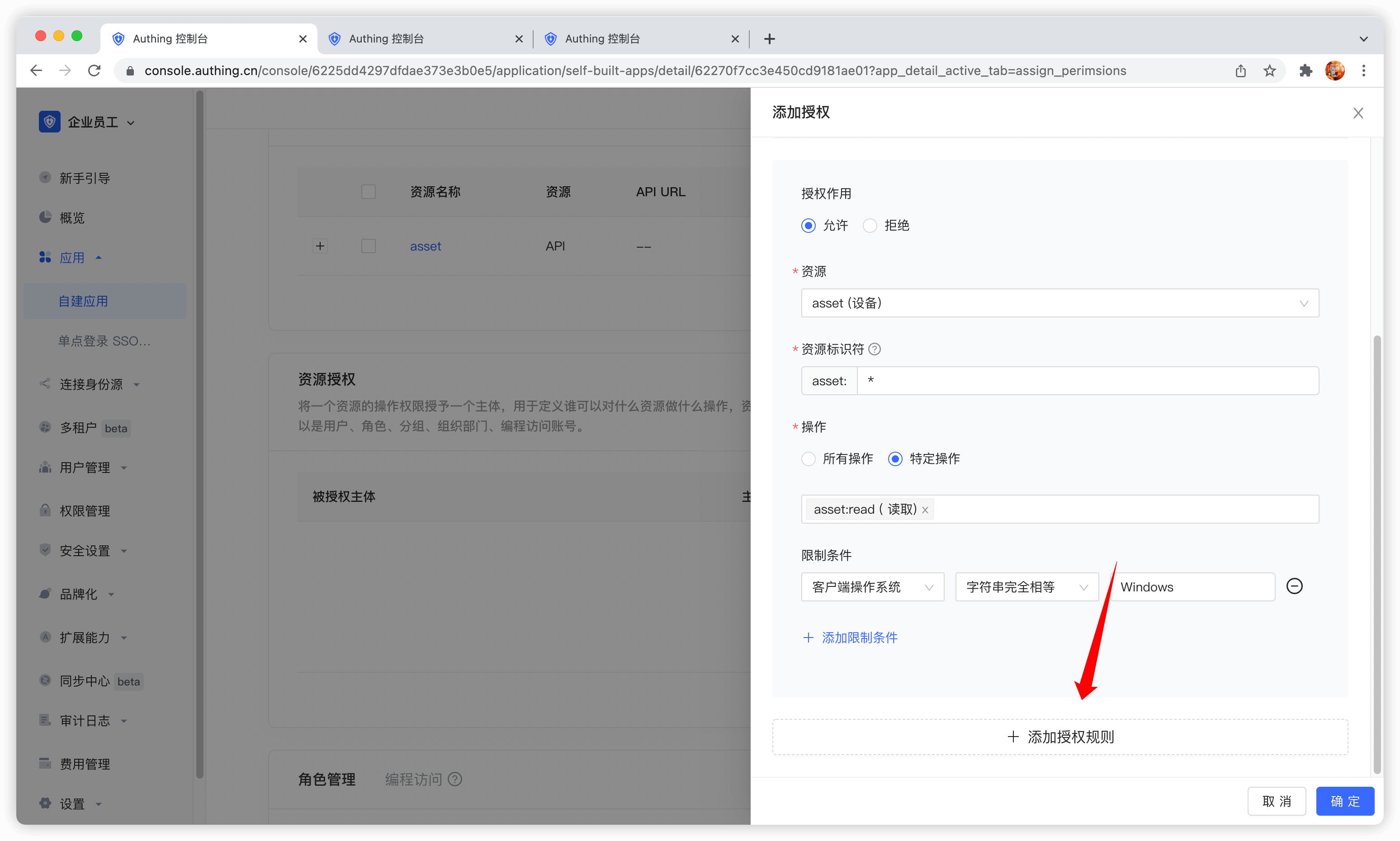
如果希望将多个资源授权给用户,可以继续添加授权规则。
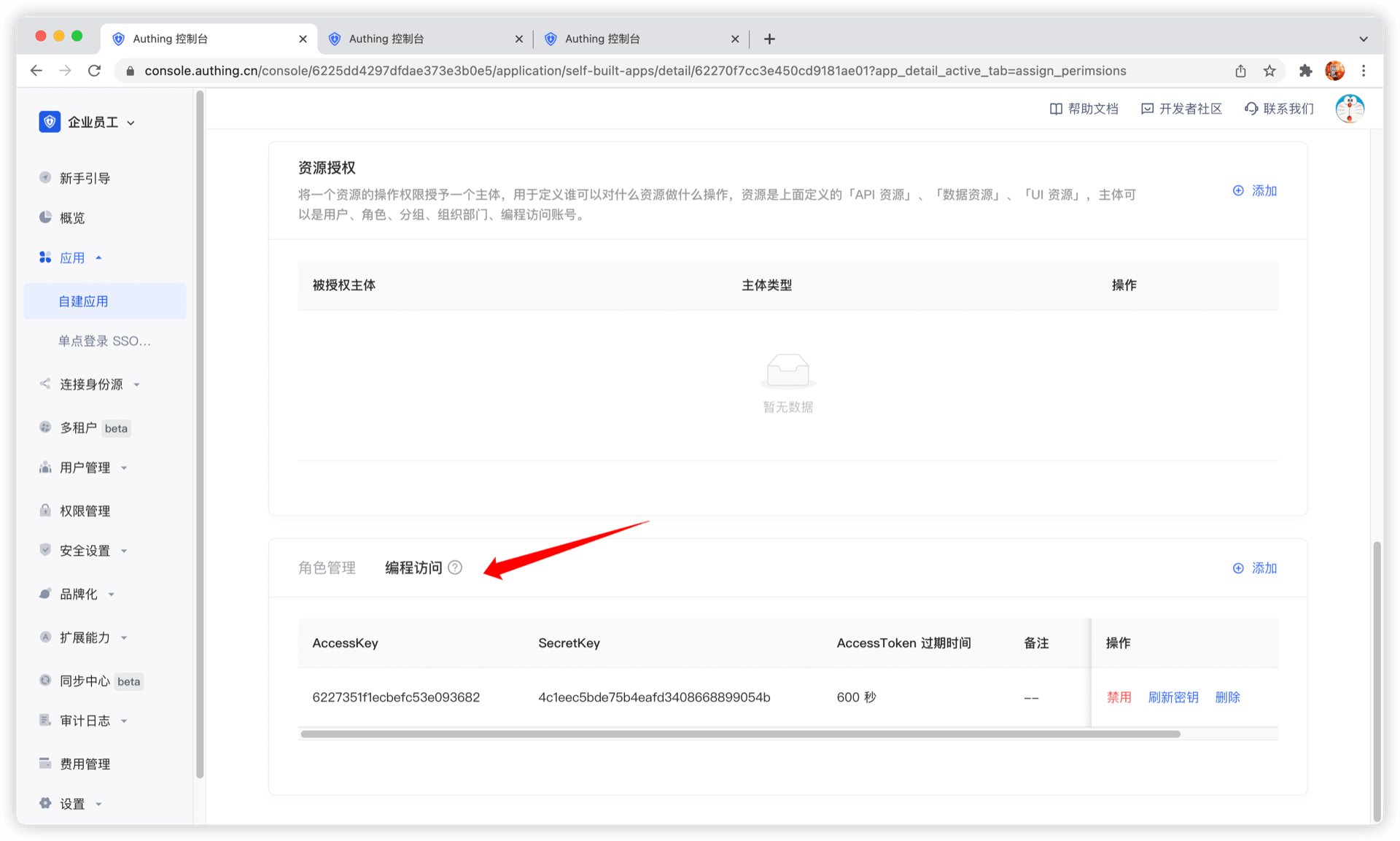
编程访问账号
编程访问账号是应用下的一对 AccessKey、SecretKey,用于交给外包商等第三方厂商。可以使用编程访问账号结合 OIDC 授权码 code 获取用户的 AccessToken 与 IdToken,或者使用编程访问账号进行 OIDC ClientCredentials 模式代表调用方本身请求授权。
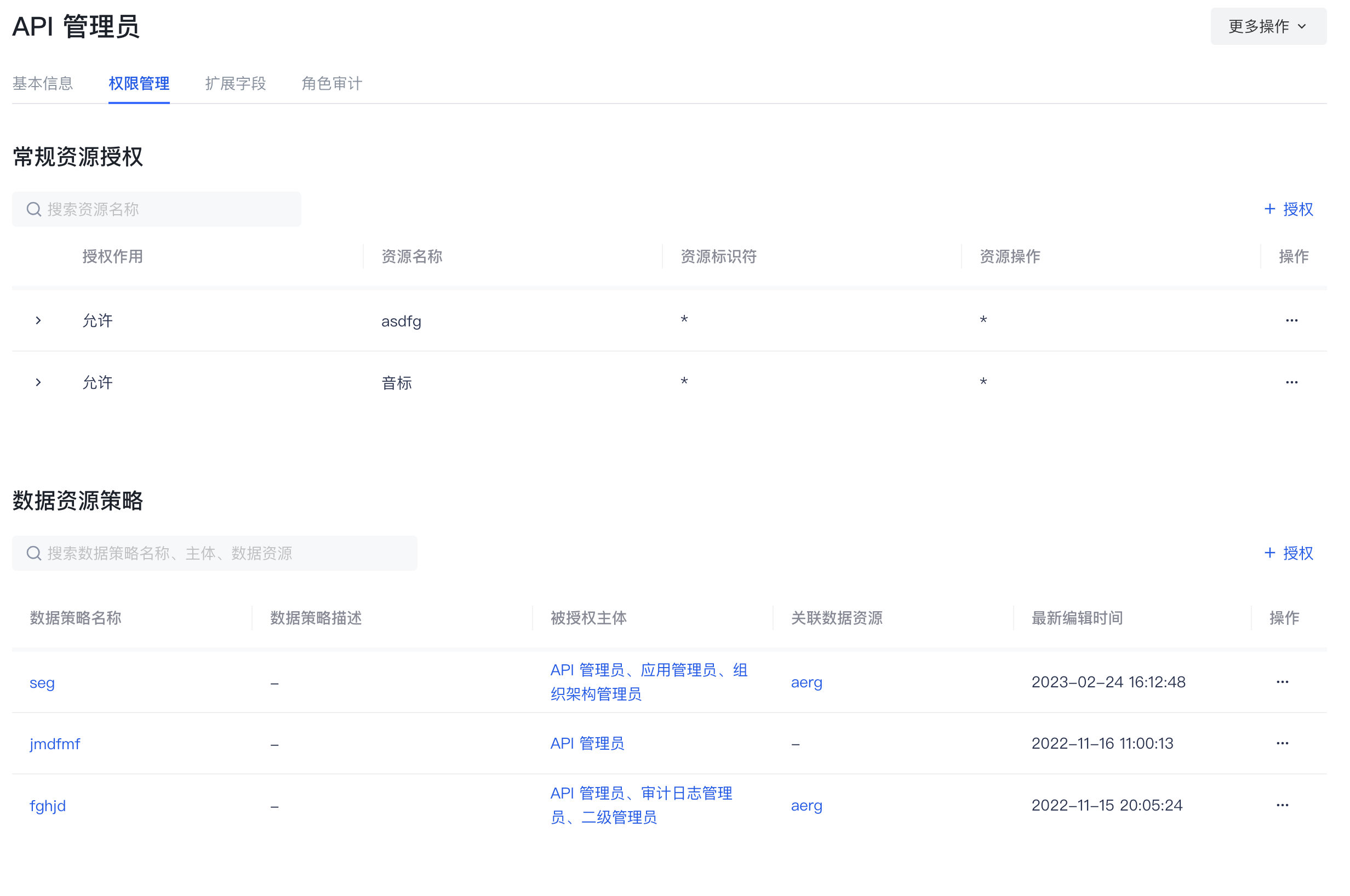
数据资源权限
随着企业业务系统越来越复杂,管理和控制对各种资源的访问权限变得越来越困难。为了确保数据安全和遵循相关法规,企业需要一种灵活且强大的权限管理工具,用以管理和监控系统中的资源访问权限。GenAuth 的数据资源权限旨在解决这一问题,帮助企业轻松管理业务系统中的场景化资源和授权。GenAuth 推荐你使用具备更强大、更灵活的权限建模与权限治理能力的数据资源权限。
- 应用场景
数据资源权限主要应用于以下场景:
- 管理具有层级结构的应用菜单,例如企业内部管理系统的侧边栏菜单。
- 管理文档目录访问操作权限,例如企业内部知识库的阅读、编辑和删除权限。
- 对其他资源进行细粒度的权限管理,例如 API 接口等。
- 解决问题
数据资源权限主要解决以下问题:
- 简化权限管理流程,提高工作效率。
- 确保数据安全,防止数据泄露和滥用。
- 支持合规性审计和报告,降低合规风险。
- 适应企业不断发展和变化的需求,支持灵活的资源管理和授权策略。
- 功能优势
- 高度灵活的资源定义和管理:GenAuth 支持对各种类型的资源进行细粒度的定义和管理,使企业能够根据实际需求灵活地配置权限策略。
- 策略化授权:基于策略的授权方式,为角色或用户分配特定的资源访问权限。策略可以包含多个资源和操作,支持灵活的权限组合和管理。
- 完整的权限视图:通过提供直观的权限视图,帮助企业快速了解和管理用户、角色和资源之间的授权关系,提高权限管理的效率。
- 审计与监控:记录用户对资源的访问操作,支持实时监控和定期审计,确保数据安全和合规性。
- 易于集成与扩展:GenAuth 的数据资源权限功能可以轻松地与现有的企业系统集成,同时支持根据客户需求进行扩展,以满足不断变化的业务需求。
通过引入 GenAuth 的数据资源权限功能,企业可以实现对业务系统中场景化资源的高效、安全和灵活的管理和授权。这将有助于降低企业的运营成本和风险,同时提高企业对数据资源访问的控制力度,确保数据安全和合规性。
GenAuth 数据资源权限主要由以下功能构成,可点击查看详细说明。
权限空间
权限空间可以理解为权限的命名空间,你可以在权限空间中创建角色、资源、管理权限,不同权限空间中的角色和资源相互独立,即使同名也不会冲突。
权限空间的主要功能
- 你可以在权限空间下创建与定义不同类型的资源
- 你可以在权限空间下创建与定义角色
- 你可以在权限空间内将资源授权给角色,再将角色授权给不同的用户与组织机构,实现基于 RBAC 模型的权限管理;你也可以在权限空间内将资源授权给用户等其他类型的主体,并设置基于条件的授权策略,实现基于 ABAC 模型的权限管理。
- 你可以在权限空间内查看与管理空间中资源权限详情
权限空间与应用的关系
当你每创建一个应用时,GenAuth 都会为你创建一个对应的权限空间,名称等同于应用名,对应的空间 Code 等同于应用 ID,且不可修改。
当你的某些业务系统无需对接 GenAuth 认证,只需要权限能力时,你也可以创建独立的与应用没有对应关系的权限空间,专门用来管理业务系统内的权限。
创建权限空间
你可以在权限列表页面,点击创建权限空间,进入创建页面: 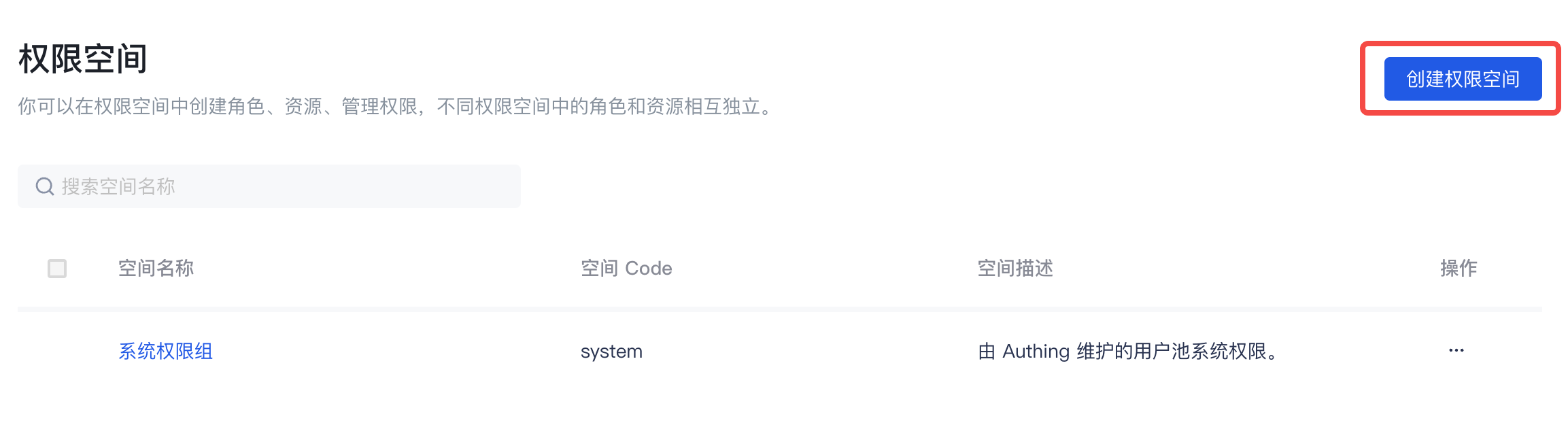
在创建权限空间时,必填空间名称与空间 code,选填空间描述,填写说明如下:
| 字段名称 | 说明 |
|---|---|
| 空间名称 | 建议使用业务系统的名称即可,例如“办公平台” |
| 空间 Code | 权限空间的唯一标识,建议使用语义化的描述,例如“OA” |
| 空间描述 | 选填 |
管理权限空间
在权限空间的基本信息页面你主要可以:
管理权限空间下的角色
- 创建权限空间下的角色
- 查看权限空间下的角色详情
- 编辑权限空间下的角色
- 删除权限空间下的角色
管理权限空间下的资源
- 创建权限空间下的资源
- 查看权限空间下的资源详情
- 编辑权限空间下的资源
- 删除权限空间下的资源
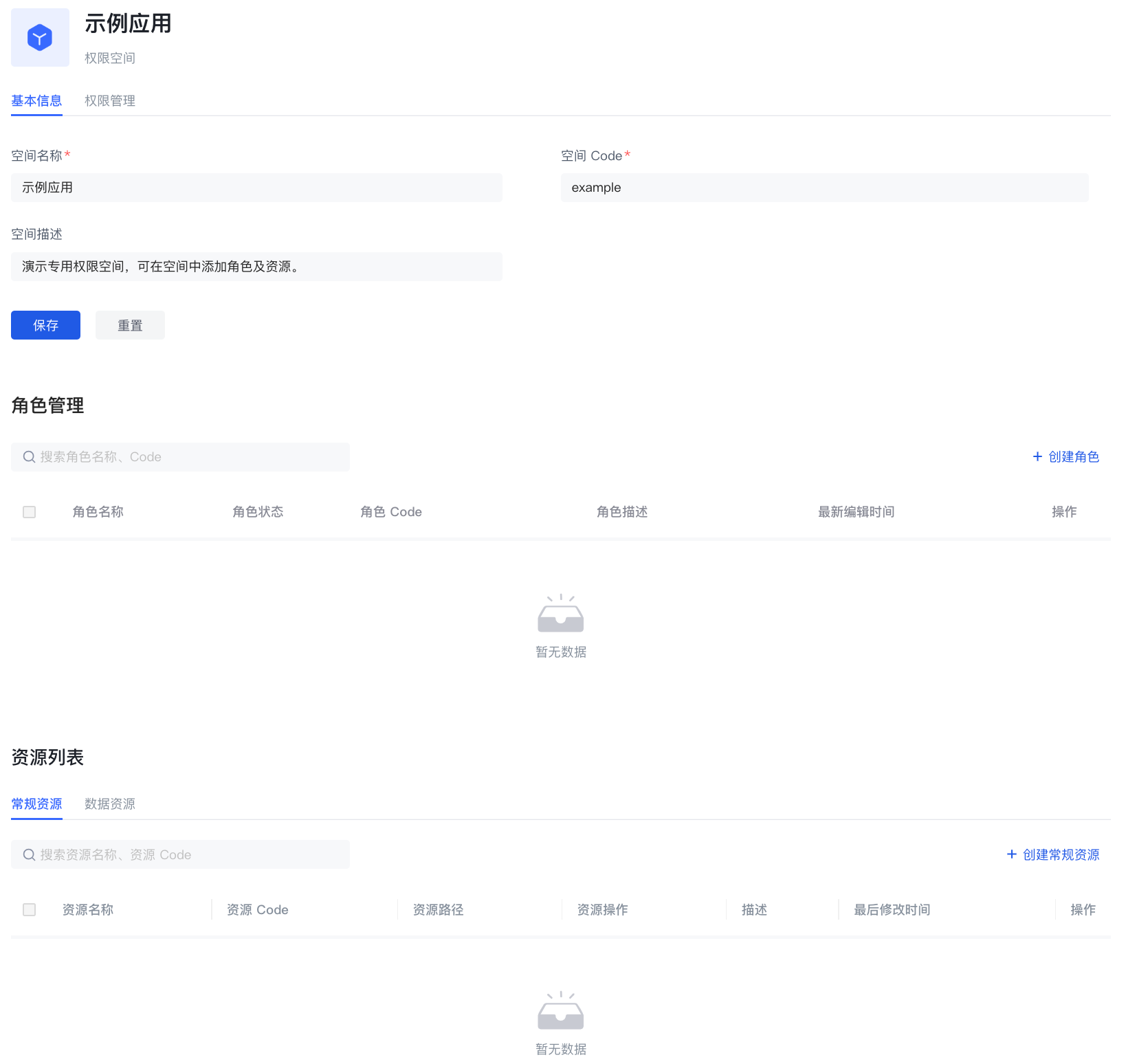
权限空间权限管理
在权限空间的权限管理页面你主要可以
- 管理权限空间下的常规资源授权
- 创建授权
- 查看与修改授权
- 删除授权
- 管理权限空间下的数据资源授权
- 创建数据策略
- 查看与修改数据策略
- 删除数据策略
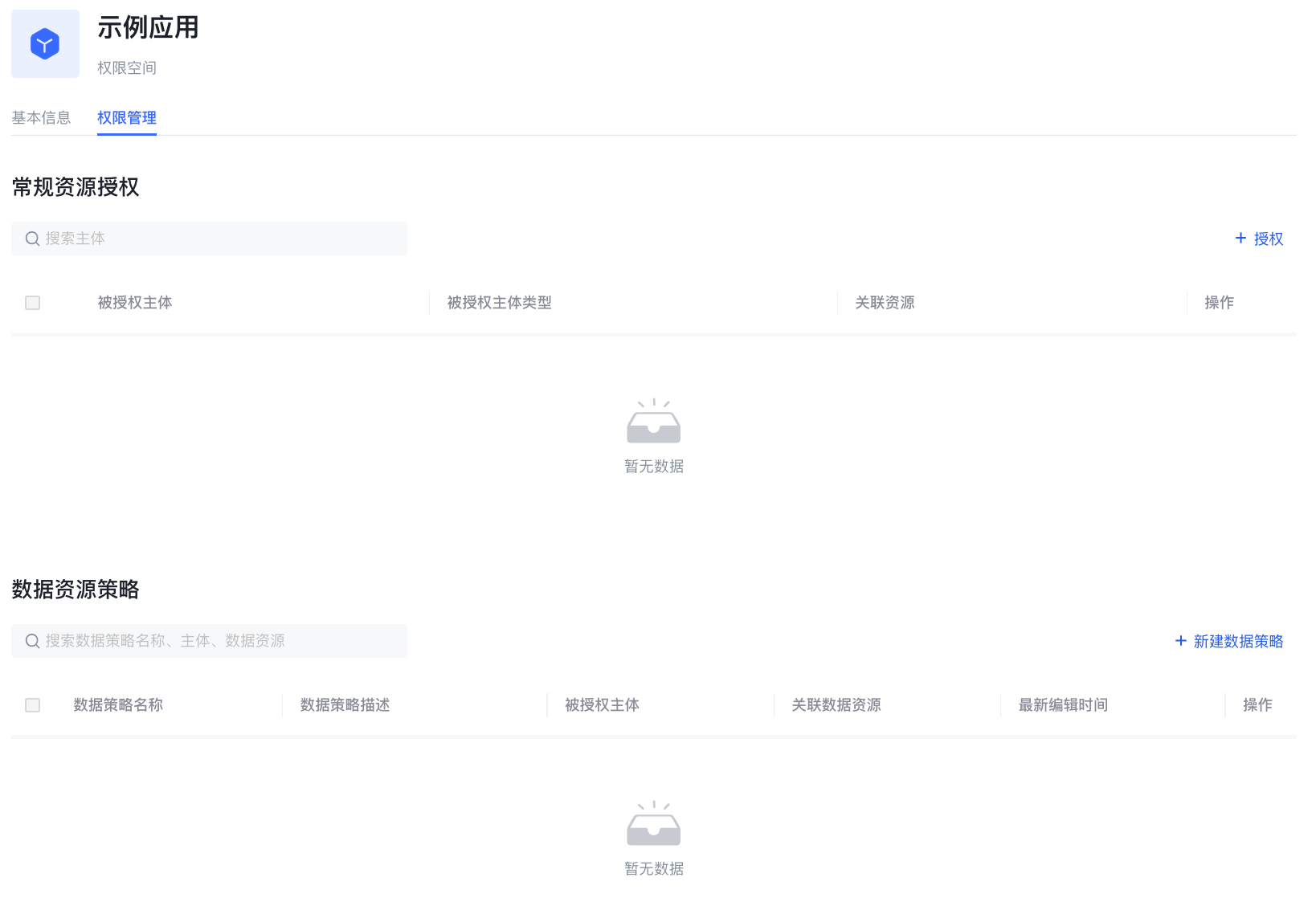
角色管理
角色是一个逻辑集合,你可以在每个权限空间下定义角色,并且授权一个角色某些资源与操作权限。当你将角色授予给用户后,该用户将会继承这个角色中的所有权限。
角色管理模块主要用来集中管理用户池内所有权限空间下的角色。
创建角色
你可以在列表页面,点击创建权限空间,进入创建页面
| 字段名称 | 说明 |
|---|---|
| 角色名称 | 根据将要授权给该角色的权限场景命名即可,例如“管理员”、“审计员” |
| 角色 Code | 角色的唯一标识,建议使用语义化的描述,例如“admin” |
| 权限空间 | 角色归属的权限空间 |
| 角色描述 | 选填 |
| 角色自动禁用时间 | 可针对临时性的角色设置自动禁用时间,禁用后角色关联的权限将被收回,可通过启用角色恢复权限 |

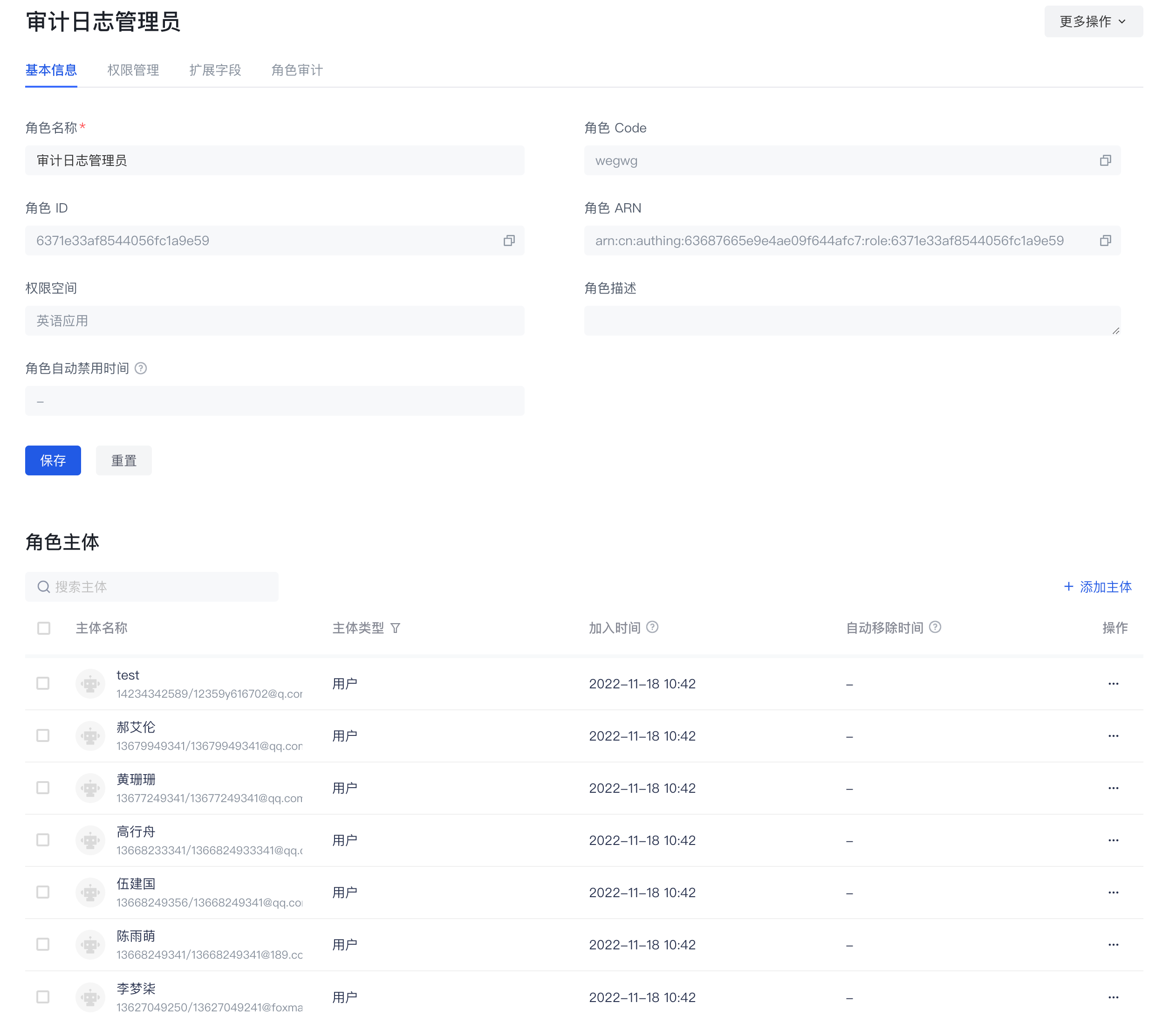
角色基本信息
在角色详情的基本信息页面,你主要可以
- 管理角色主体
- 添加角色主体
- 添加指定用户成为角色主体
- 添加指定组织成为角色主体
- 添加主体时支持设置主体自动移除时间
- 查看角色主体
- 移除角色主体
- 添加角色主体
- 管理角色的基本信息
- 查看角色基本信息
- 角色名称
- 角色 Code
- 角色 ID
- 角色 ARN
- 角色所属权限空间
- 角色描述
- 修改角色名称、角色描述
- 查看角色基本信息
角色权限管理
在角色详情的权限管理页面,你主要可以
- 管理角色关联的常规资源授权
- 将常规资源授权给当前角色
- 查看与修改当前角色关联的常规资源授权
- 移除当前角色关联的常规资源授权授权
- 管理角色关联的数据资源授权
- 将数据策略授权给当前角色
- 查看已授权给当前角色的数据策略与详情
- 移除已授权给当前角色的数据策略
角色审计
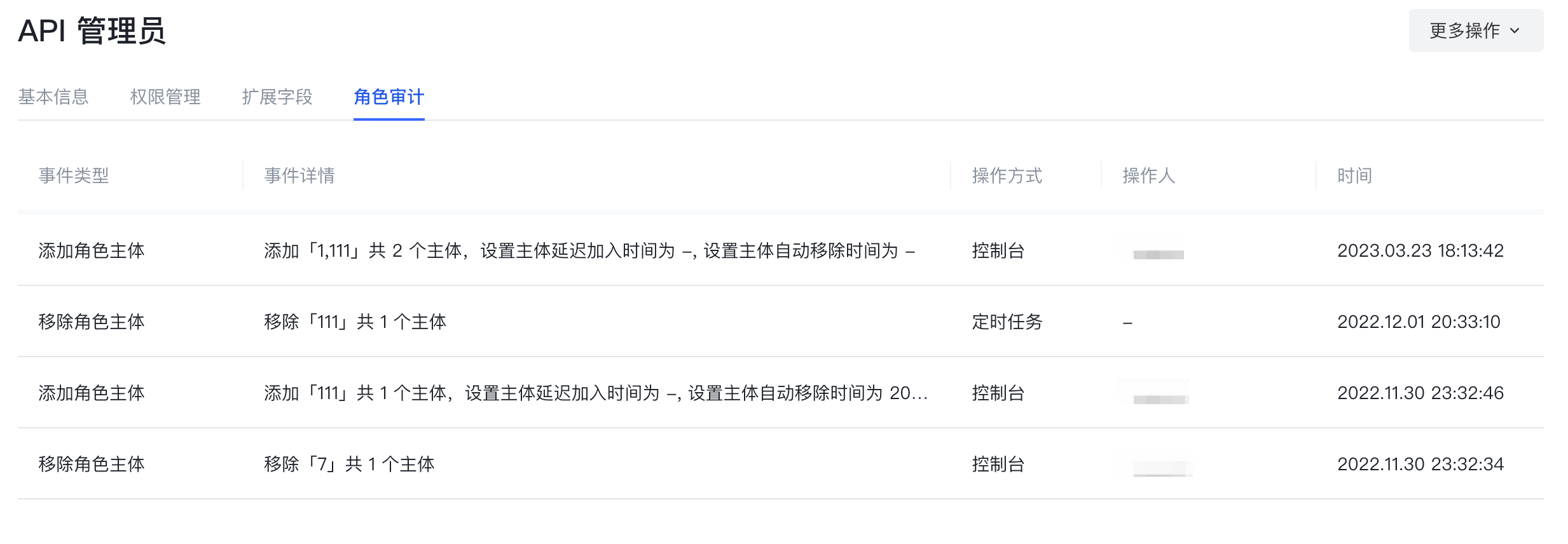
在角色详情的角色审计页面,你可以查看当前角色的历史变更记录,主要包括
- 创建角色
- 给角色添加主体、移除主体
- 给角色添加授权、移除授权
数据资源
数据资源是更贴近实际业务数据权限管理场景的资源,在数据资源权限管理中可以实现菜单、文档目录、API、合同等多种类型资源的定义、授权及权限视图查询的完整闭环。
数据资源提供三种资源结构类型,分别是树结构类型、数组结构类型和字符串结构类型,以便于用户便捷创建对应结构的资源,每种类型有其独特的数据结构,每种类型的数据资源有很多的应用场景。进入数据资源权限管理页面时可编辑查看整个用户池内数据资源列表,点击右上角的创建数据资源可以选择数据类型。

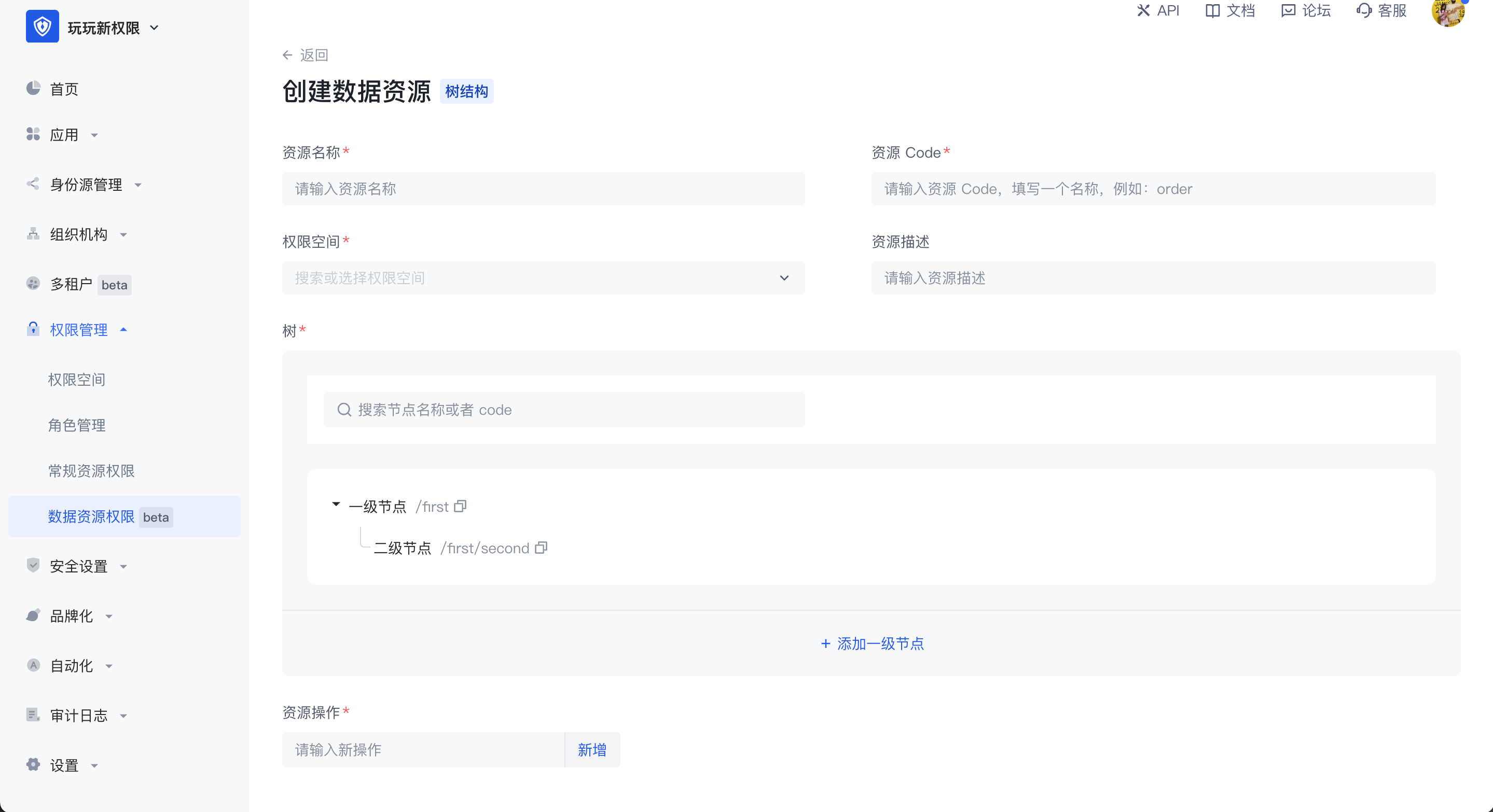
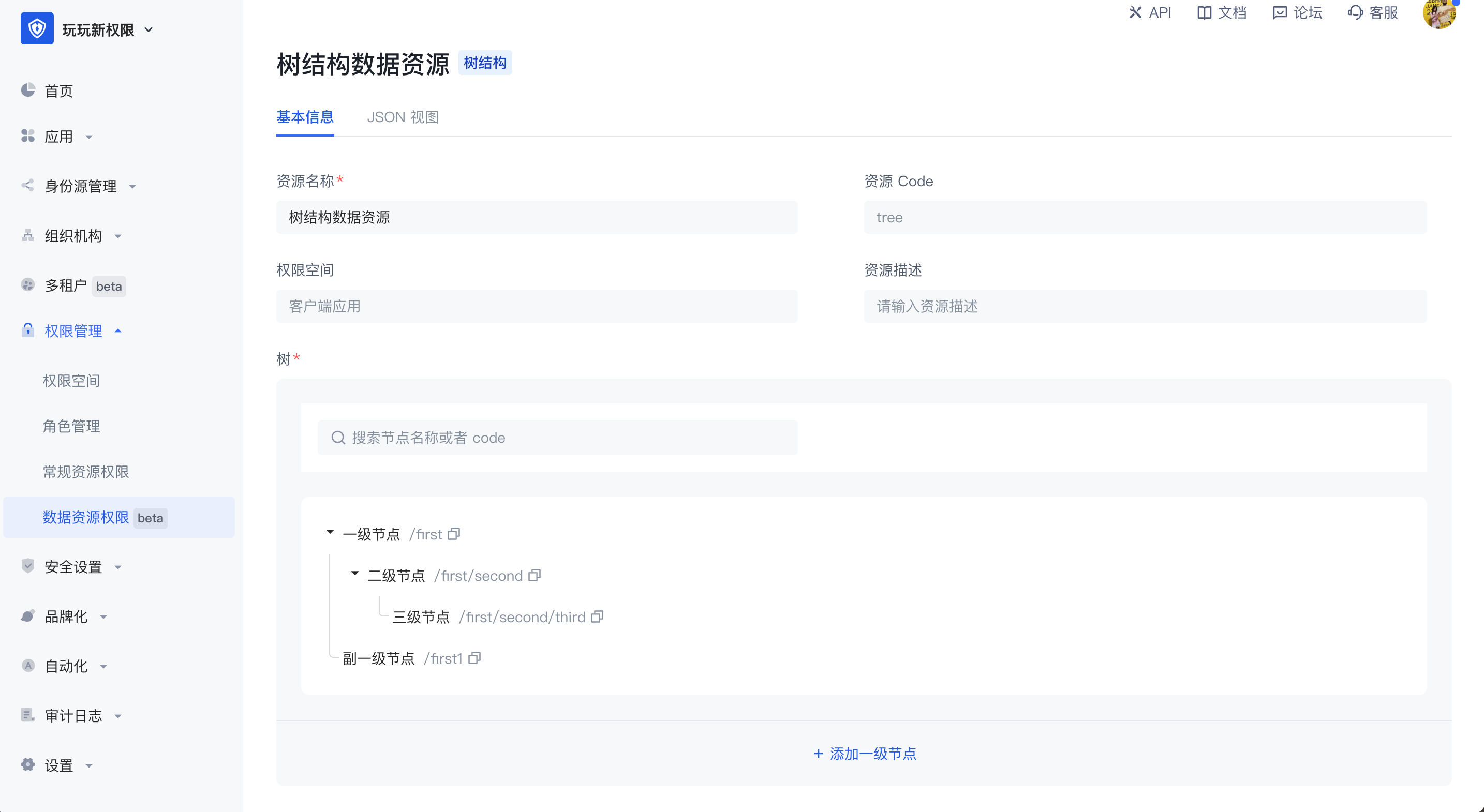
- 树结构
树结构数据资源有两种常见的应用场景,分别是树结构的菜单和有目录层级的文档系统。在管理菜单资源的场景下,当超级管理员想将系统菜单设置为权限管理中的资源,想要实现各个菜单管理员能有权限使用不同的菜单资源时,可以将菜单拆为不同的资源并将其授权给不同的主体对象,树结构是有层级的,可自定义每个节点中的值,在树结构中可以创建子节点,也可以创建同层级的节点。
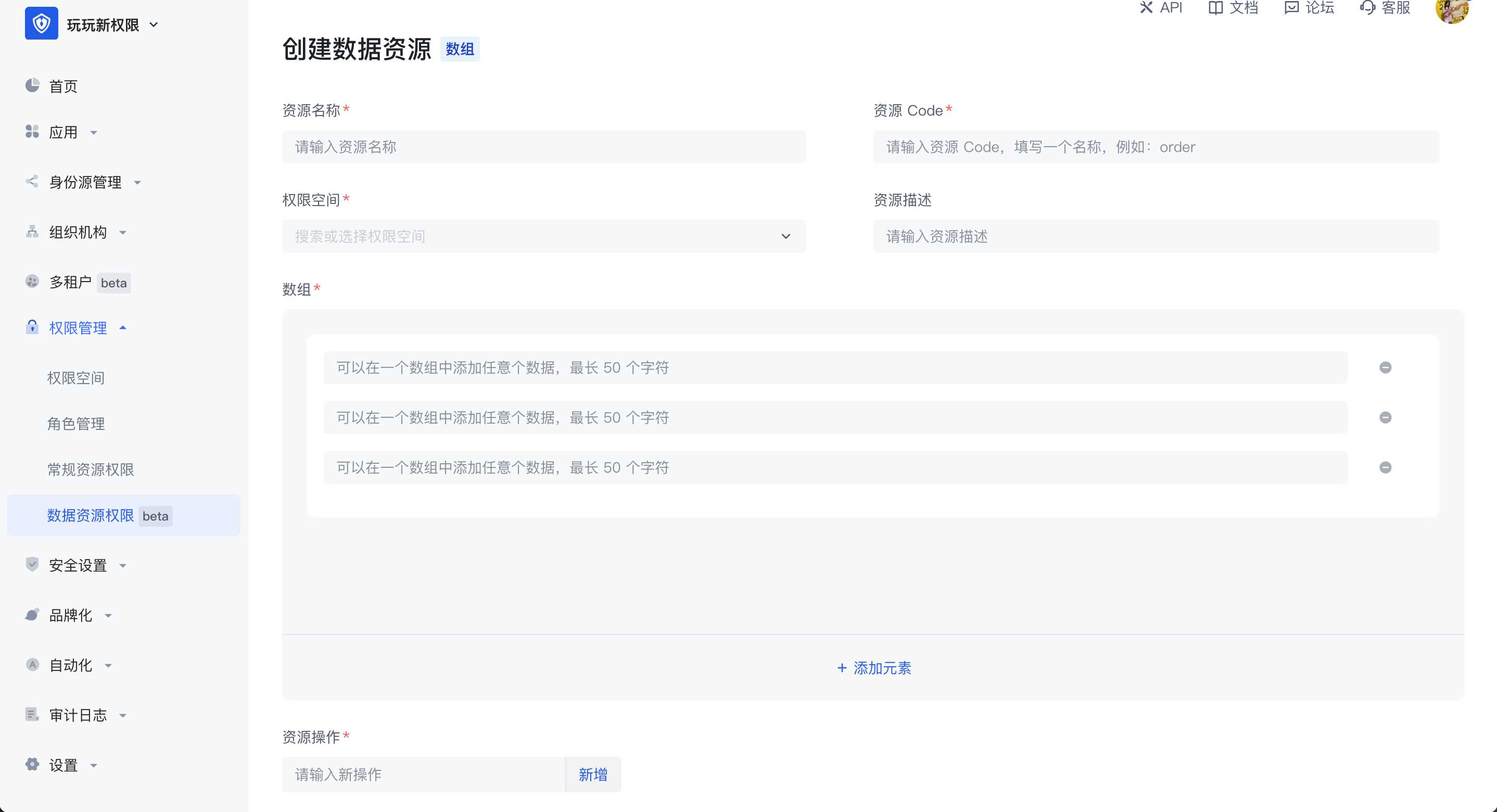
- 数组结构
数组结构的数据资源常见的应用场景是合同条款等数据管理,可以添加多条数组结构的数据资源,可以在一个数组中添加任意个数据,最长 50 个字符。
- 字符串结构
字符串结构的数据资源常见的应用场景是对 API 等资源的管理,一般用于路径指代,在字符串数据资源中可以不受限制的输入多行文本内容,或将 API 路径填入实现对 API 的资源管理。
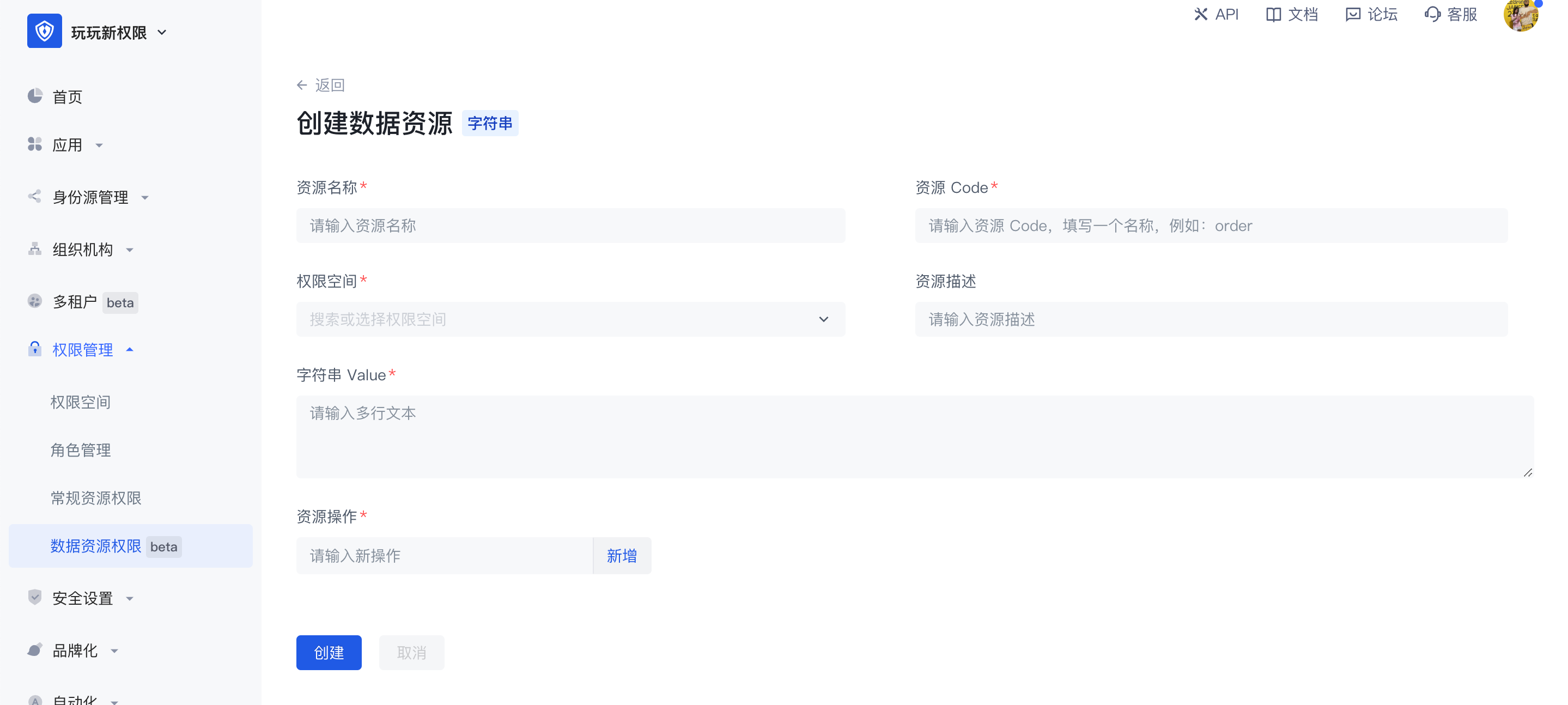
数据资源区别于常规资源的地方在于:
- 数据资源提供了三种常见的数据资源类型,能购方便用户更灵活的创建各种类型的资源;
- 授权方式,数据资源不能直接授权给主体对象,需要打包成策略后授权,常规资源可以直接授权给角色。
数据资源详情:创建好数据资源后,可在资源详情页中查看、编辑资源中的值,创建后资源中的权限空间和资源 code 不可修改。
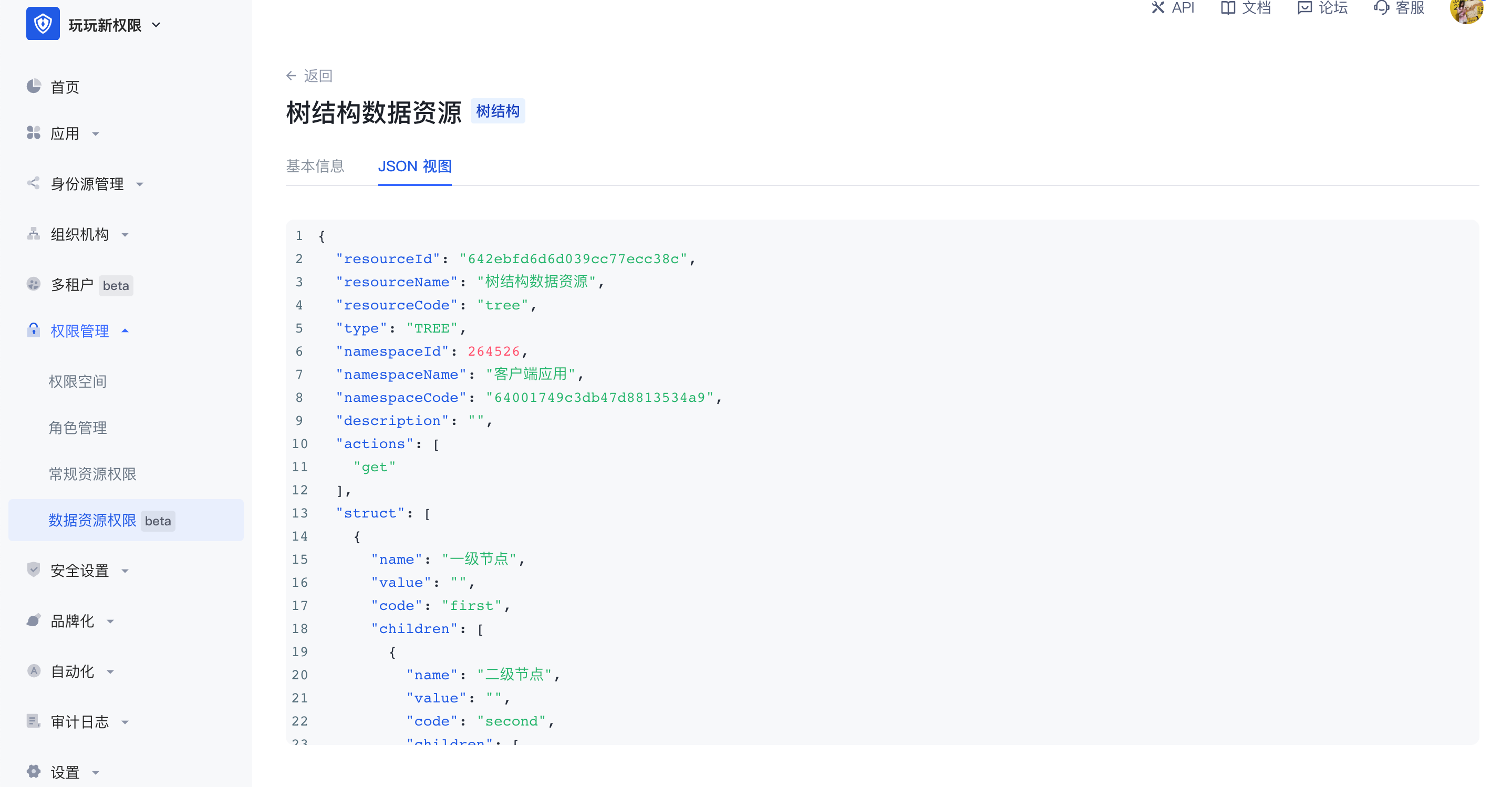
JSON 视图:支持在资源详情中能通过 JSON 的方式查看资源的数据化的表示。
数据策略与授权
数据策略
数据策略:把若干个资源、操作、授权作用和限制条件打包在一起,叫做一个策略。
在数据策略列表中,可以查看所有数据策略授权主体和关联数据资源,并支持对数据策略进行新增、编辑修改和删除。
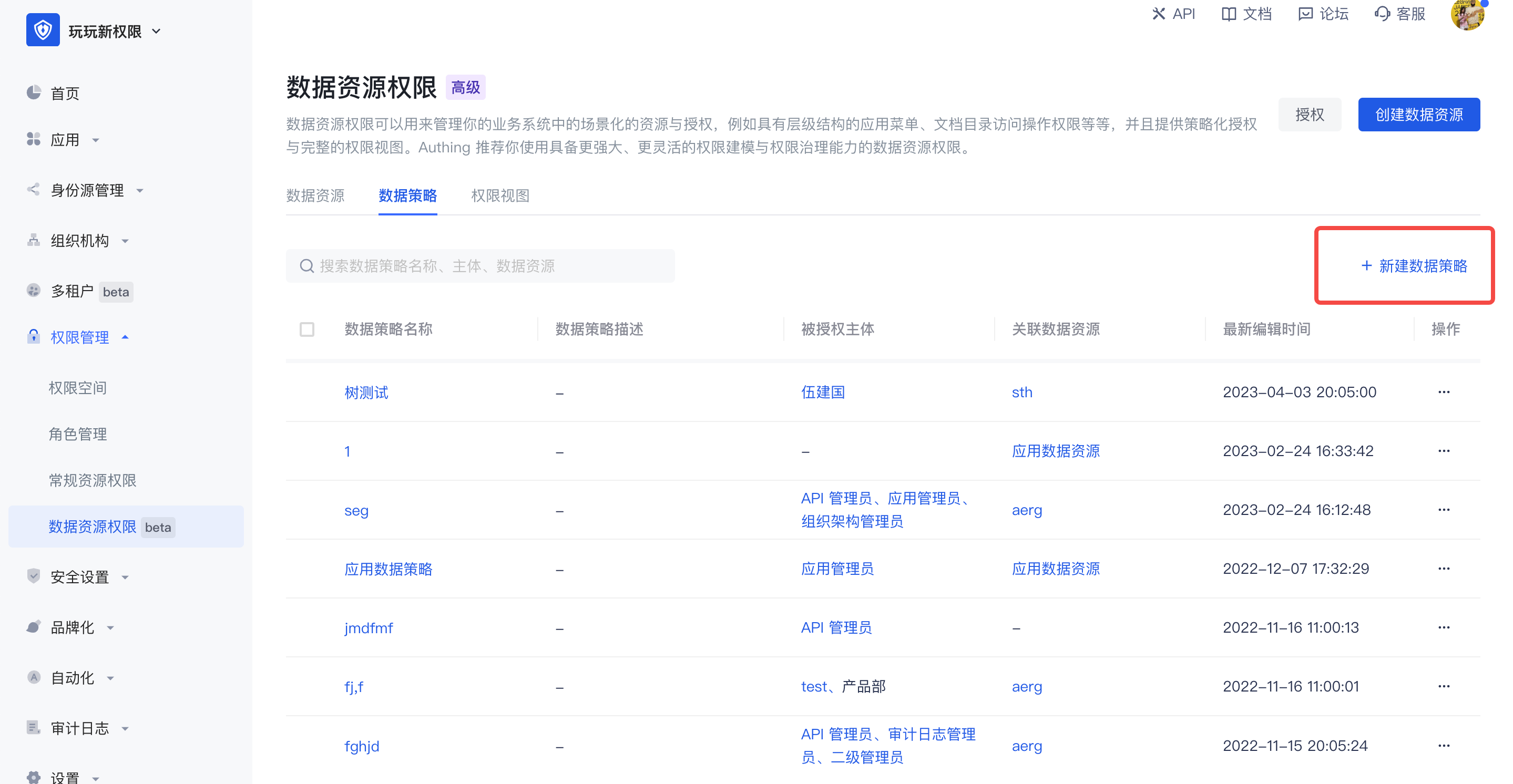
在新建数据策略时,有两种编辑方式:
可视化编辑策略
一个策略中可以有多个数据权限,每一个数据权限都需要先选择授权作用,然后再选择权限空间中的资源及关联操作,在此基础上还可以添加权限限制条件,最终将资源打包到一起形成一个数据策略。
在数据策略中支持跨权限空间选择资源。如果资源是树结构的数据资源,选择粒度细化,也可以选择某个层级的节点。
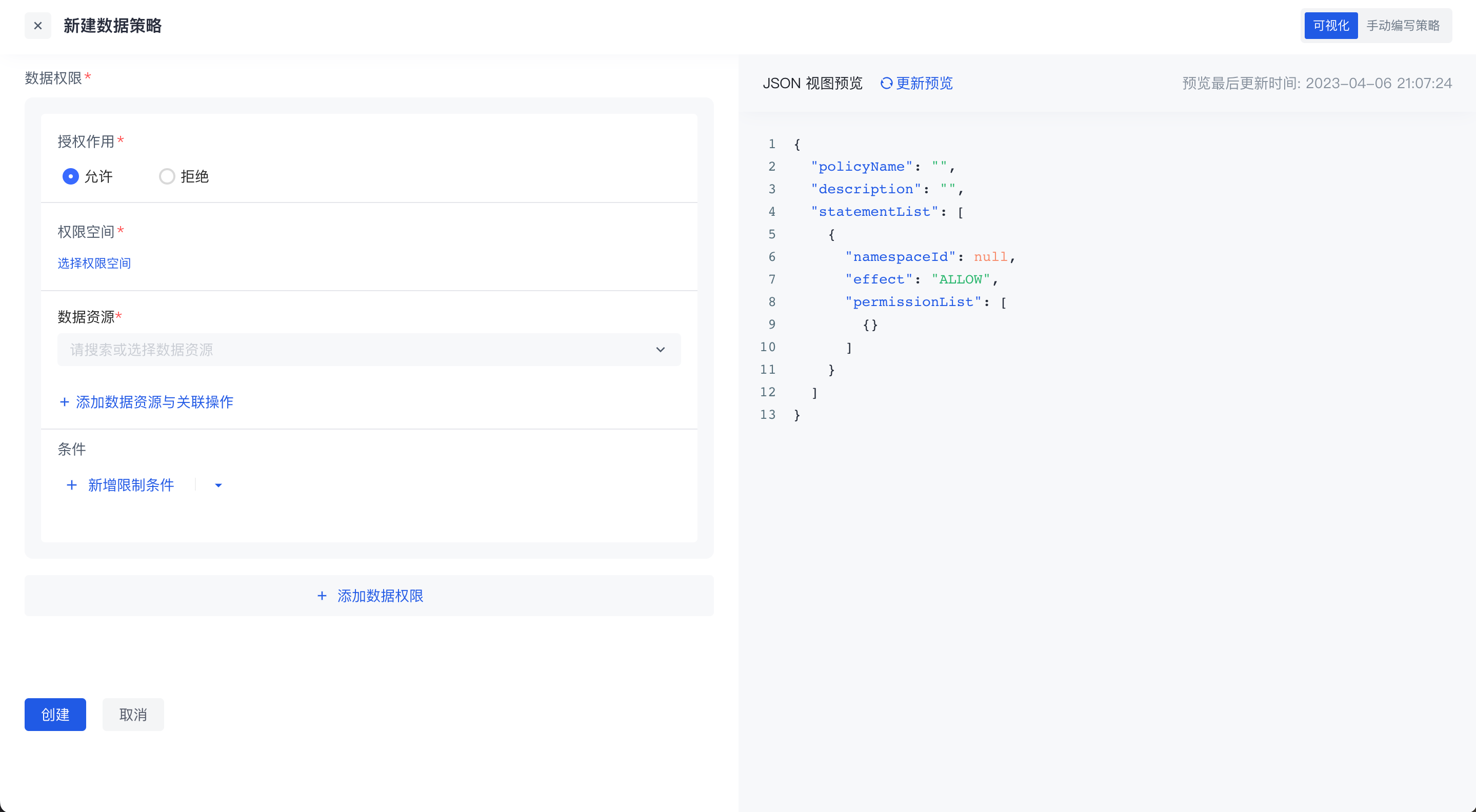
手动编写策略
切换右上角的手动编写策略,可以通过 DSL 编写数据权限策略。

点击左上角的编写条件,还支持通过 rego 语言编写数据权限策略中的条件。详见数据策略与 OPA
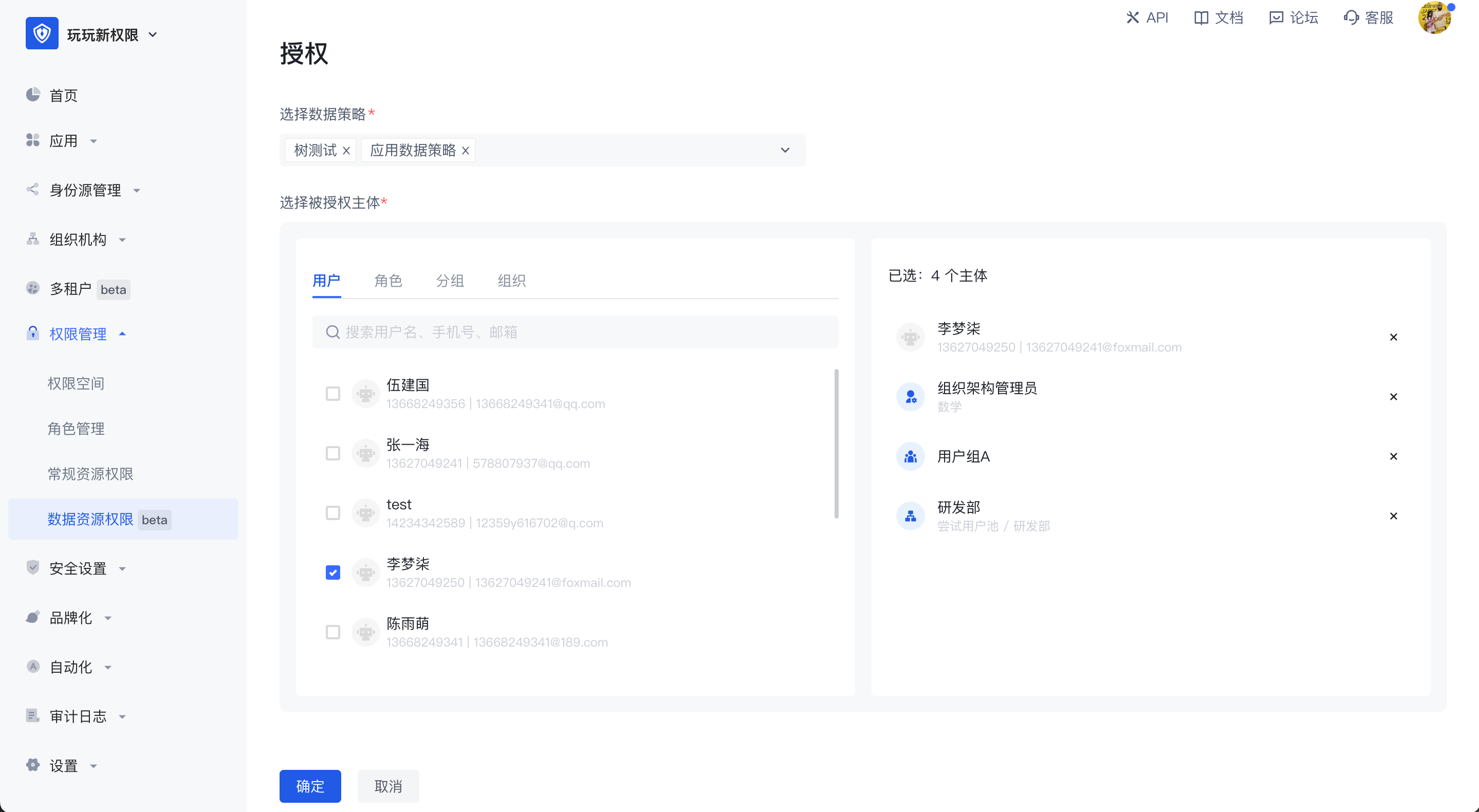
授权
策略打包好后,点击权限管理页面右上角的 授权 按钮,将其授权给某个主体,可以将一个或多个数据策略同时授权给多个跨不同类型的授权主体。
数据策略与 OPA
Policy:根据形势而确定的原则和方法。比如说:当我们生病了,就要去医院看医生,这就是一条策略,编程语言中的if、switch关键字就是很好的体现。
Open Policy Agent 简称OPA是一个使用Go语言编写的开源通用策略引擎。我们编写的代码中可能存在大量的策略,它和服务高度耦合,一旦有所改动,需要重新编译或重新部署。OPA 就能帮我们解决这一痛点,它将策略和服务进行解耦(即策略脱钩,Policy Decoupling),这些策略独立于应用程序而存在。
官网地址:https://www.openpolicyagent.org/
OPA 的使用
OPA 提供了丰富的RESTful API,我们需要做出策略决策时候,会查询 OPA 并提供结构化数据(JSON)作为输入。注意:OPA 接受任意结构化数据作为输入
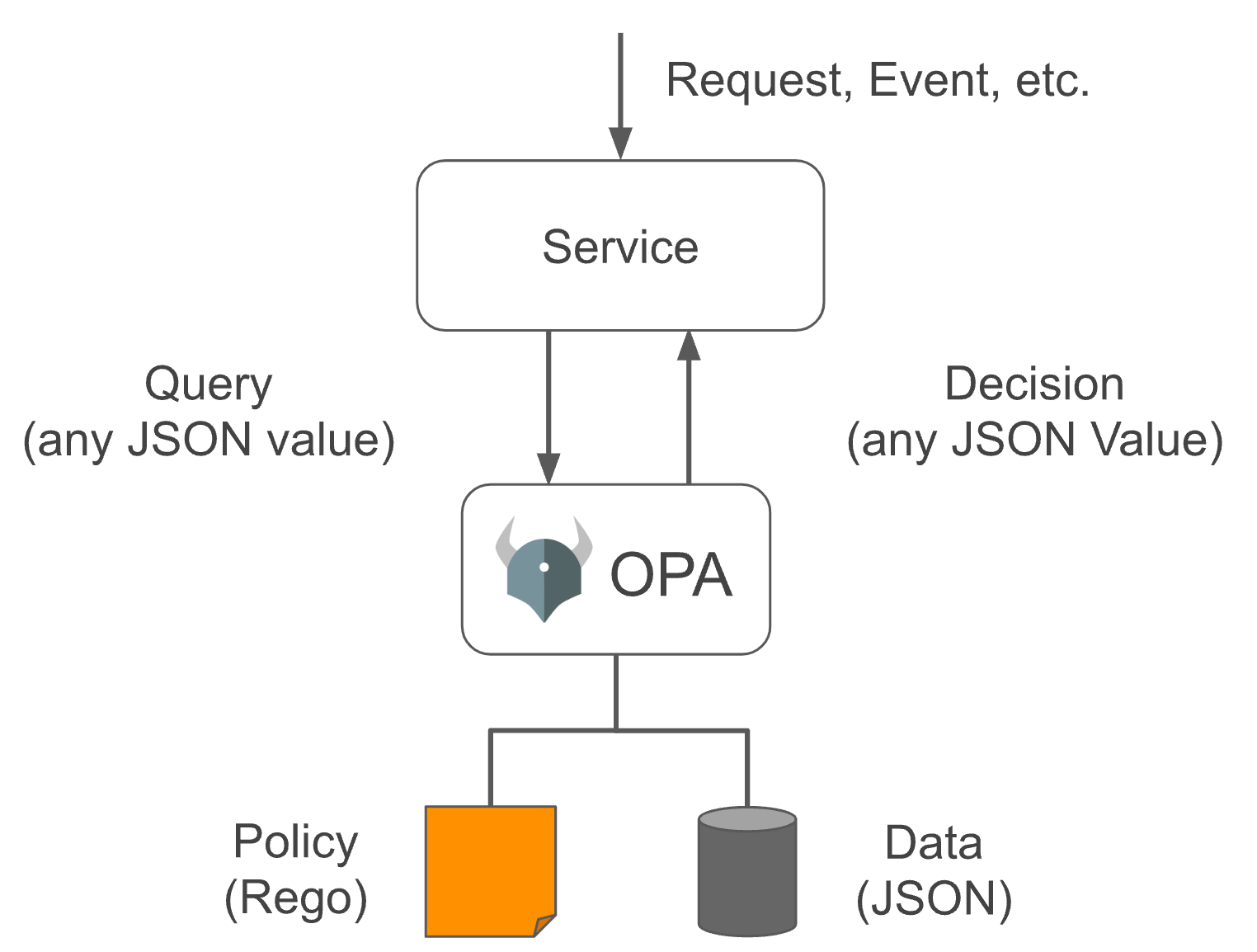
在 OPA 中对于它的输入一般称为input,可以为任意类型,输出也一样可以为任意类型,即可以输出布尔值 true 或 false,也可以输出一个JSON字符串对象。
我们的权限管理实现了基于属性的访问控制(Attribute-based access control - ABAC),它背后的实现原理是将数据策略中定义的一组组条件转换成 OPA 的策略,并在需要的时候让其帮我们做策略决策(OPA 还有很多用法)
如何定义 OPA 策略
OPA 中策略使用Rego语言编写的,Rego 的灵感来自 Datalog,它是一种易于理解、已有数十年的历史的查询语言。Rego 扩展了 Datalog 以支持 JSON/YAML 等文档模型,对于它的详细介绍请参考官方文档https://www.openpolicyagent.org/docs/latest/policy-language/#what-is-rego
OPA 中的策略在模块(Module)中定义,Module 包含:Package、Import、Rule,除了 Package 是唯一且必须的,另外两个可以 0 或多个。其中 Rule 又是由 Head(定义变量)、Body(定义表达式) 组成。整个 Module 的**抽象语法树(AST)**如下:
Module
|
+--- Package (Reference)
|
+--- Imports
| |
| +--- Import (Term)
|
+--- Rules
|
+--- Rule
|
+--- Head
| |
| +--- Name (Variable)
| |
| +--- Key (Term)
| |
| +--- Value (Term)
|
+--- Body
|
+--- Expression (Term | Terms | Variable Declaration)Rego 编写的策略通常在文本文件中定义,在运行时由 OPA 去解析和编译,所以在数据策略中编写 Rego 条件,会转换成字符串:
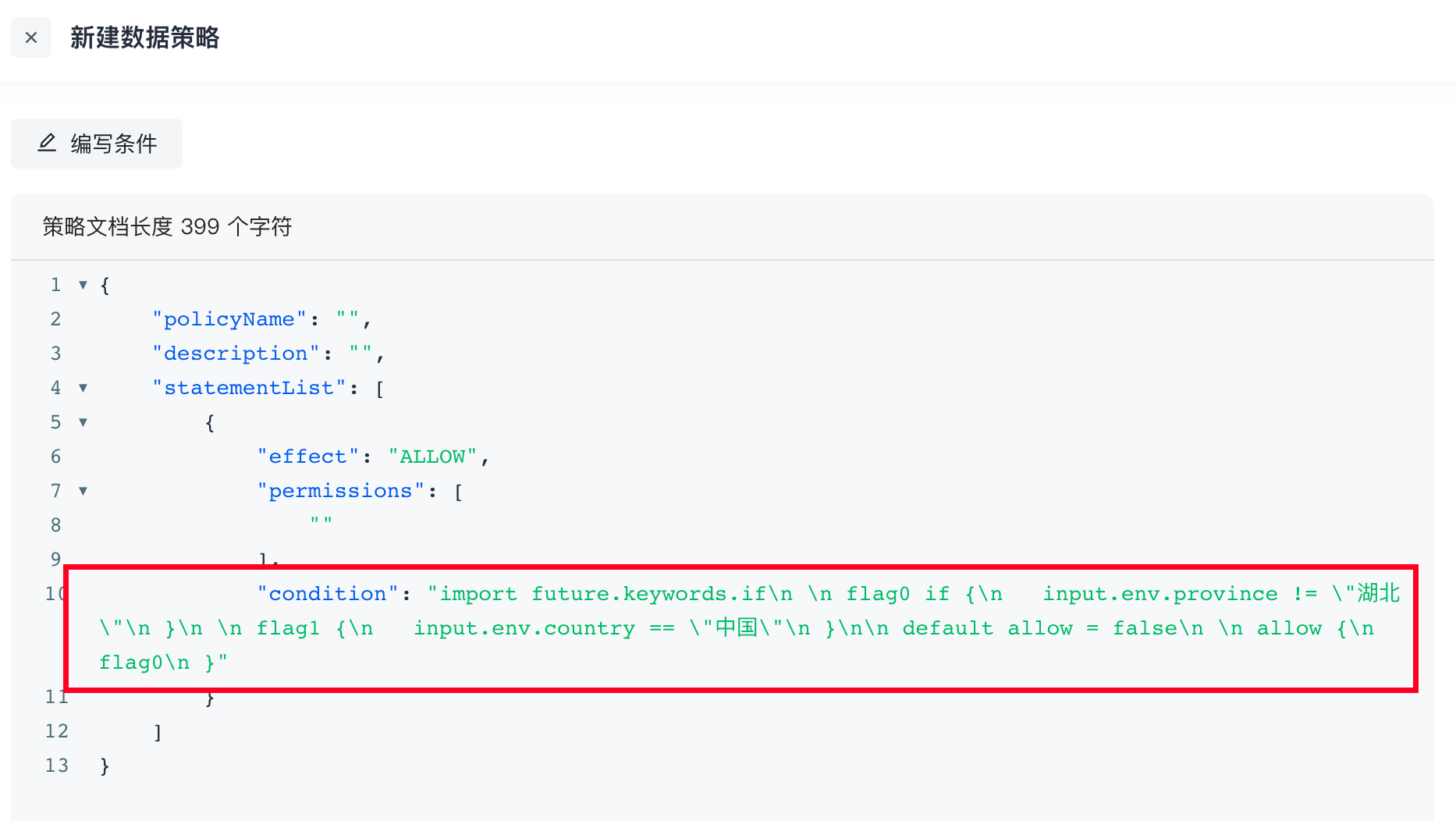
案例
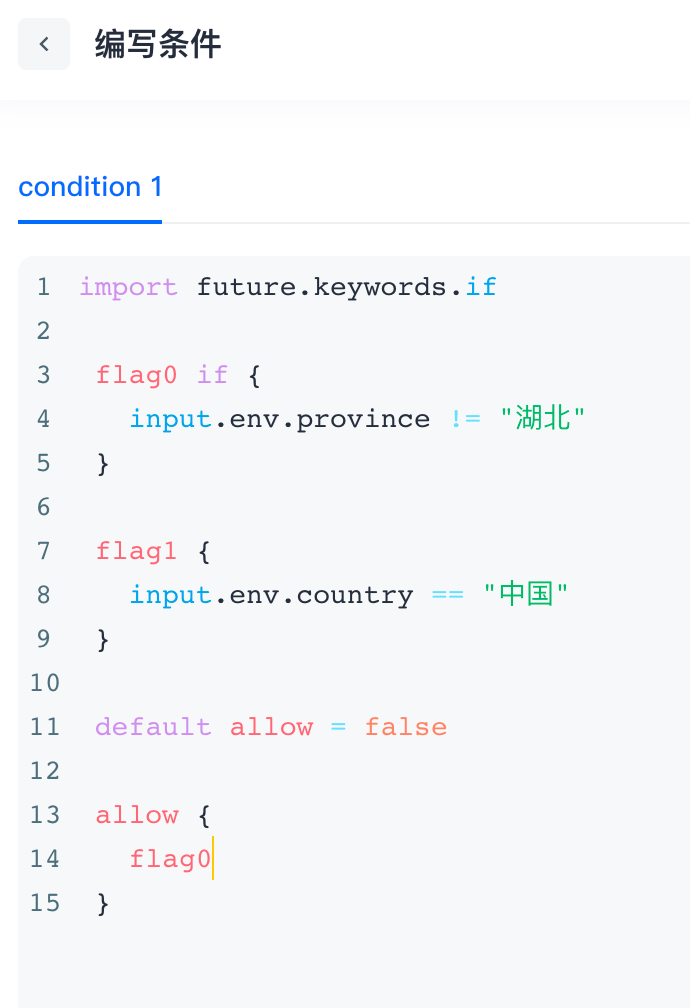
判断下当前的请求是否满足 IP 属于:10.109.201.100、10.109.201.101、10.109.201.102这三个;请求时间不在早上 5-8 点之间;并且浏览器是 Chrome 或者 Safari。下图是通过表单的方式的配置:
我们根据这个案例,使用 Rego 进行编写,如下:
# 包声明
package play
# 如果引用了外部包,则需要使用 improt 声明
# if 是一个非默认的关键字,所以需要引用
import future.keywords.if
# 声明一个 isChrome 变量,默认值为 false,由于使用 default 进行声明,不论它是否为 true 或 false,OPA 一定会输出给用户
default isChrome = false
# 此处使用 if 关键字,它仅仅是用来提高表现力,实际是可以省略的
isChrome if {
# input 是系统保留字,表示用户的输入,即当我们执行这条策略时,输入的数据都能够通过 input 进行获取
# 此处判断输入数据中 env.browserType 是否为 Chrome,使用 `` 定义字符串 OPA 更为推荐的方式,也可以使用 ""
input.env.browserType == `Chrome`
}
# 从 default 声明到当前组成一个 Rule,这个Rule中有仅有一条表达式,它返回的值会被赋予给 isChrome
# 省略 if 也是可以的;
# isSafari 没有使用 default 声明,如果不为 true 则不会被 OPA 输出给用户,我们只需要一个最终结果,所以可以省略
isSafari if {
input.env.browserType == `Safari`
}
# 下述代码片段表述逻辑关系中的"或",即浏览器类型匹配 Chrome 或者 Safair 之一,browserTypeIsMatch 则为 true
browserTypeIsMatch if {
isChrome
}
browserTypeIsMatch if {
isSafari
}
ipIsMatch if {
# 此处定义一个了集合,[_]表示对这个集合进行迭代,每次迭代的数据都会交给 temp
temp = {`10.109.201.100`, `10.109.201.101`, `10.109.201.102`}[_]
temp == input.env.ip
}
# 多个条件必须同时满足,即逻辑关系中的"且",则写在同一个代码片段中即可,每一行都以";"结尾,换行则可以省略
requestTimeIsMatch if {
# 此处判断请求时间不在早上 5-8 点之间,我们将 5 点和 8 点以 0 点开始换成秒数,即为 18000 和 28800
input.env.requestTime < 18000
}{
input.env.requestTime > 28800
}
#
# 防止不统一,所以我们约定每个策略都必须使用 default 声明一个名为 allow 的变量,以至于我们都能通过 API 获取到执行的结果
# 因为上面 3 条规则的逻辑关系是"且",所以在定义一个布尔类型变量,汇总最终的结果
# 因为使用 default 声明,所以 OPA 一定会返回给我们,最后判断整个条件是否满足则观察 allow 的值是否为 true 即可
default allow = false
allow if {
browserTypeIsMatch
ipIsMatch
requestTimeIsMatch
}官方提供了一个 Playgroud,支持在线执行,整个界面窗口分为如下四块:
- 左侧一整块是
Policy窗口,在此处使用 Rego 进行编写策略 - 右上方是
Input窗口,规则需要的外部数据在此处定义,可以JSON或YAML数据格式 - 右中间是
Data窗口,如果规则需要的数据是来源于持久化数据库,我们可以为策略进行绑定其存储层接口,不过我们这里不需要,所以无需关注 - 右下方是
Output窗口,OPA 进行策略决策后的结果输出区域,在 playground 这种方式中会将全部信息都输出给我们,没有办法指定查询指定的字段值,官方提示的示例中输出为布尔值。
我们将编写好的 Rego 代码在 Playground 中去执行,如下:
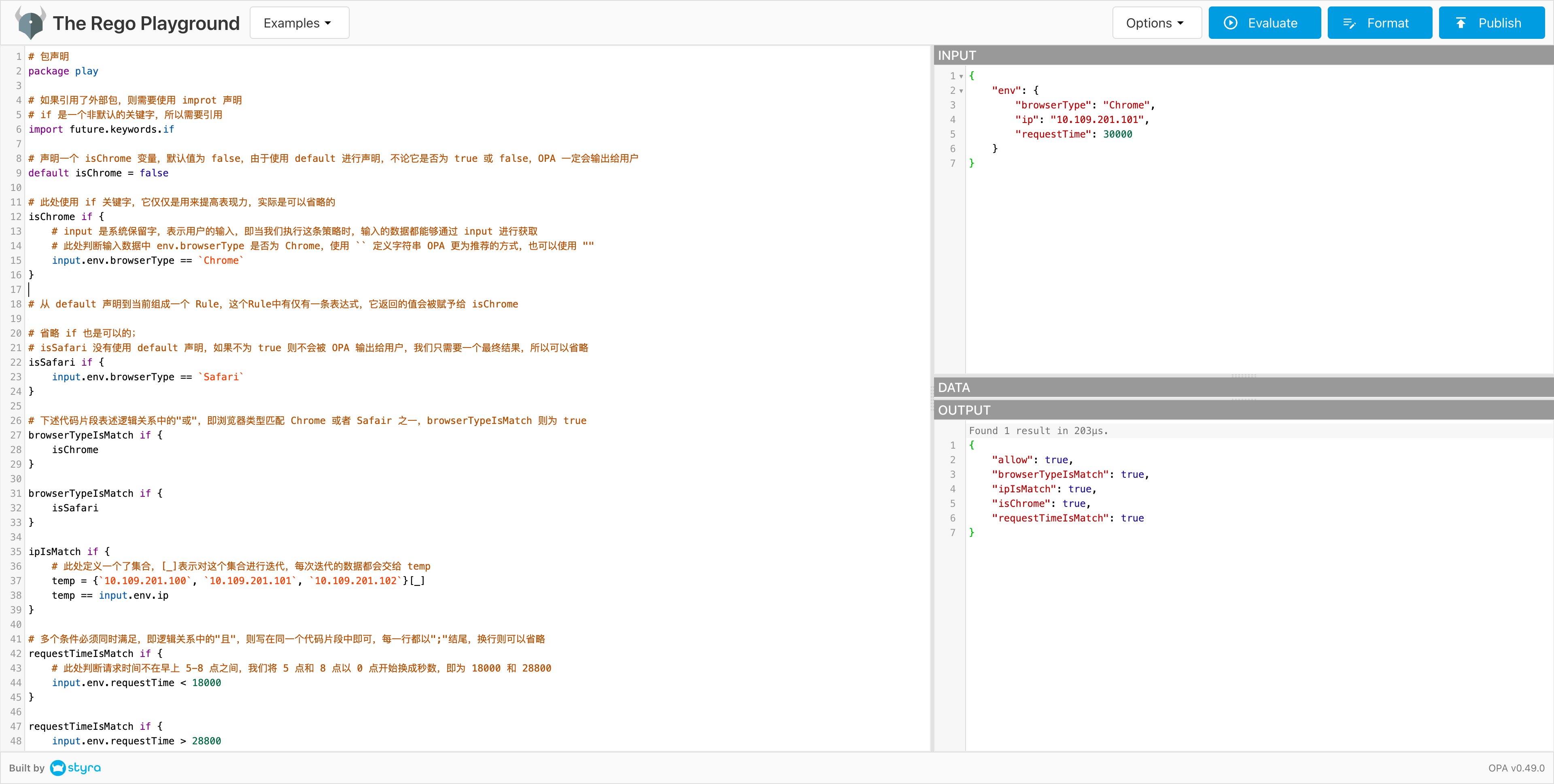
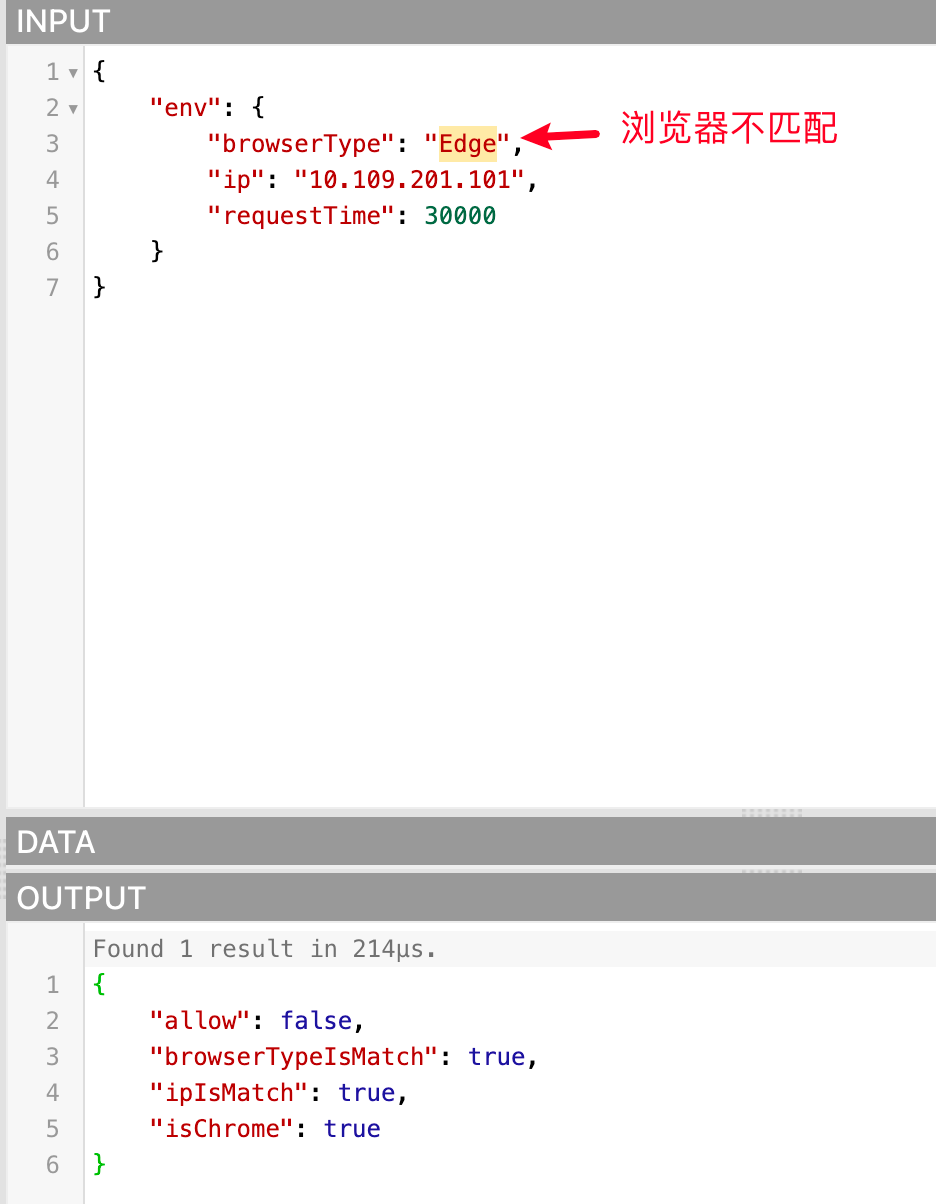
因为传入的数据都是符合条件的,所以allow为true,我们也可以试着传入不匹配的数据,看看 allow 是否为false,如下:
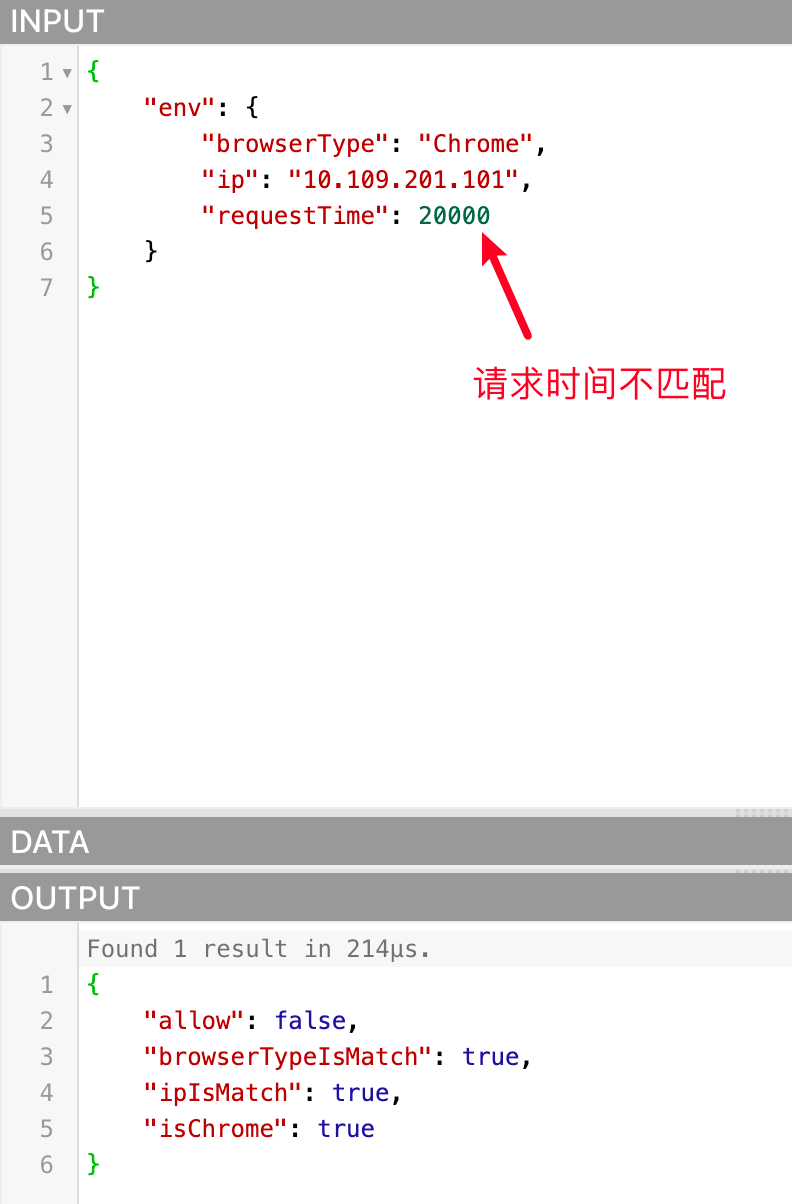
数据策略使用 Rego 语言编写条件的注意事项
package无需声明,由于我们开放用户自定义 Rego,防止包名相同冲突,所以由程序自行生成,用户则不需要关注,不声明即可- 部分鉴权 API 支持传入本次请求相关的环境参数,数据策略配置了条件,程序会将这些参数传递给 OPA,那么在编写的 Rego 条件中,则可以通过 Rego 语言的系统保留字
input配合参数所属属性名进行获取,这些参数名称如下:- env:环境属性
- ip(IP)
- city(城市)
- province(省份)
- country(国家)
- deviceType(设备类型)
- systemType(系统类型)
- browserType(浏览器类型)
- requestDate(请求时间,格式:yyyy-mm-dd hh:mm:ss)
- requestTime(请求时间时分秒部分总和的秒数,鉴权时会根据请求参数中的 requestDate 进行计算后额外添加此参数)
- env:环境属性
示例案例
- 获取本次鉴权请求的 IP:input.env.ip
- 获取本次鉴权请求的设备类型:input.env.deviceType
后期我们可能会放开更多的属性,如:用户池、应用、用户等等,获取方式类似,比如放开 user 属性,获取用户名,则可以通过 input.user.username
- 由于OPA 提供查询策略执行结果的 API 必须传入结果中存在一个变量的变量名,所以我们约定 Rego 编写的条件,必须使用 default 关键****字定义一个布尔类型且名 allow 的变量,我们判断条件是否命中时,会向 OPA 查询该策略执行结果中
allow变量的值,如果为true则表示条件命中,授权成立
Rego 代码示例
为降低用户学习 Rego 成本,我们根据数据策略目前支持配置的几种条件,提供了一些常用的 Rego 代码片段示例:
- 请求地址信息是在中国湖北省武汉市
countryIsMatch {
input.env.country == "中国"
}
provinceIsMatch {
input.env.province == "湖北"
}
cityIsMatch {
input.env.city == "武汉"
}
default allow = false
allow {
countryIsMatch
provinceIsMatch
cityIsMatch
}- 请求 IP 属于:10.109.201.100、10.109.201.101、10.109.201.102
ipIsMatch {
temp = {`10.109.201.100`, `10.109.201.101`, `10.109.201.102`}[_]
temp == input.env.ip
}
default allow = false
allow {
ipIsMatch
}- 请求设备类型是 PC 或者 Mobile
deviceTypeIsMatch {
input.env.deviceType == "PC"
}
{
input.env.deviceType == "Moblie"
}
default allow = false
allow {
deviceTypeIsMatch
}- 请求请求时间在早上 0-8 点之间(将 8 点以 0 点开始换成秒数,即为 28800)
requestTimeIsMatch {
input.env.requestTime >= 0
input.env.requestTime <= 28800
}
default allow = false
allow {
requestTimeIsMatch
}权限视图
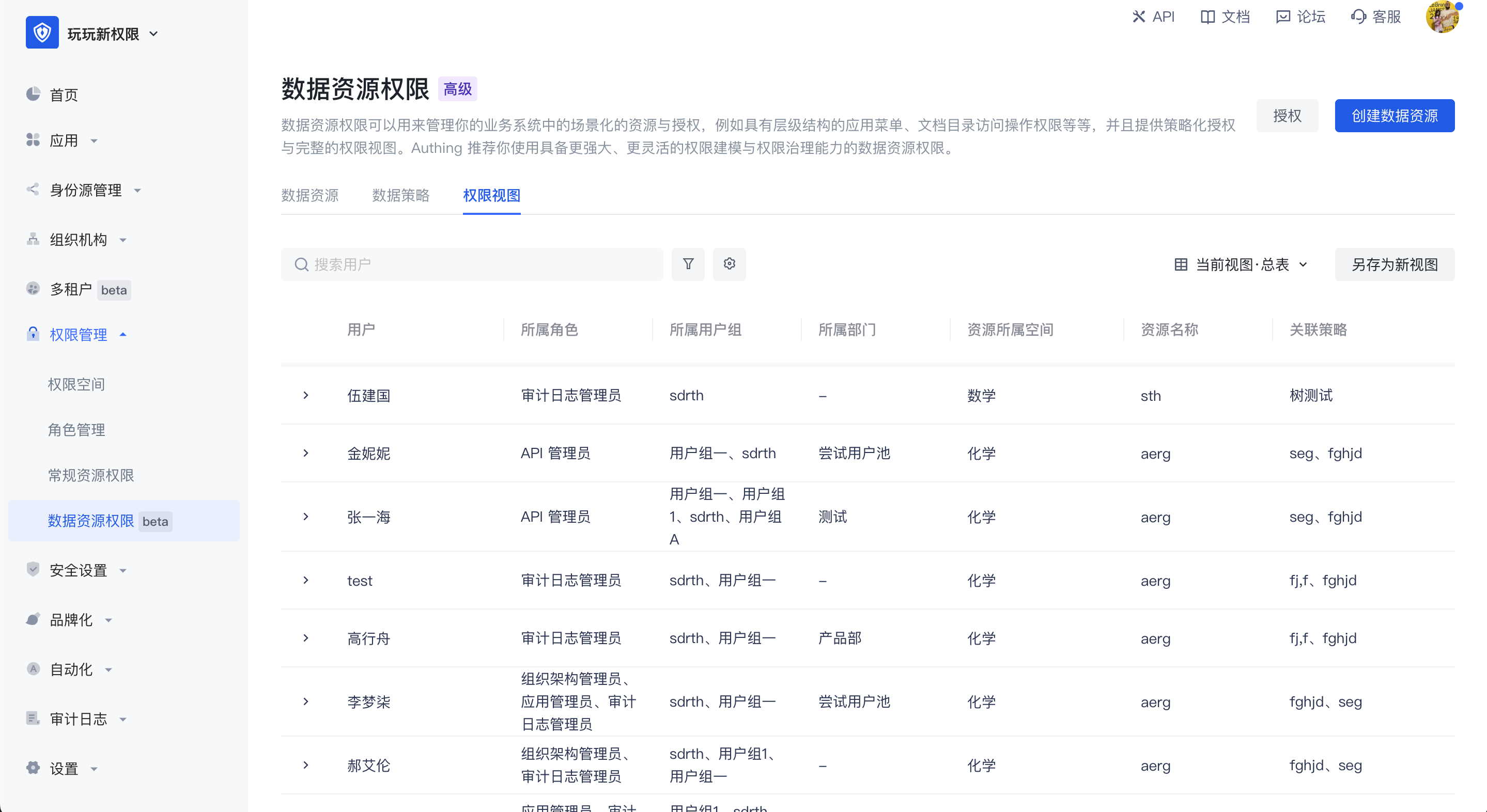
权限视图:在权限视图中,以用户为维度去计算授权关系,在视图中可以查询到每个用户有哪些权限,策略中对应有哪些资源,以及对应的是哪个权限空间。
管理员可将权限视图用作权限审计。通过数据策略,资源关联到了用户上,不管这个用户归到哪个用户分组,或属于哪个角色,或属于哪个部门,最终都会以用户的维度来呈现用户最终的权限。
在权限视图中支持通过筛选字段生成新的权限视图,并支持另存为新视图及进行视图之间的切换。