Benchmark Evaluation
LoCoMo
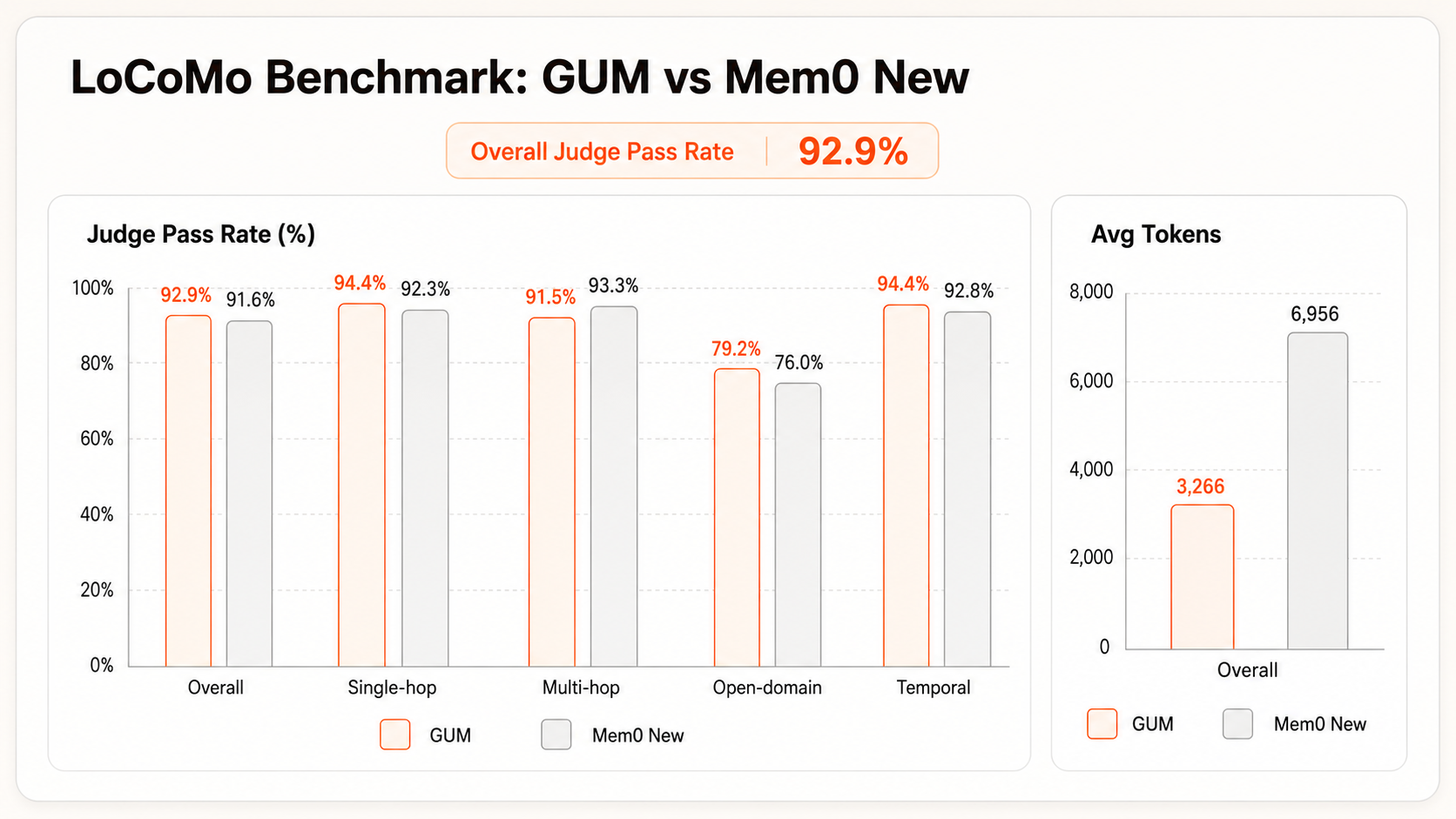
LoCoMo is a commonly used benchmark for long-conversation memory. It covers cross-turn, cross-topic, and temporal questions, making it useful for testing whether an Agent can recall stable user facts and events from long histories. GUMem reaches 92.9% accuracy, which is currently SOTA-level performance.
| Product | Overall | Single-hop | Multi-hop | Temporal | Open-domain |
|---|---|---|---|---|---|
| GUMem | 92.90 | 94.40 | 91.50 | 94.40 | 79.20 |
| Mem0 New April 2026 | 91.60 | 92.30 | 93.30 | 92.80 | 76.00 |
| HyperGraphRAG | 86.49 | 90.61 | 80.85 | 85.36 | 70.83 |
| MIRIX | 85.38 | 85.11 | 83.70 | 88.39 | 65.62 |
| HippoRAG 2 | 81.62 | 86.44 | 75.89 | 78.50 | 66.67 |
| LightRAG | 79.87 | 86.68 | 84.04 | 60.75 | 71.88 |
| MemOS | 75.80 | 81.09 | 67.49 | 75.18 | 55.90 |
| Membase | 72.01 | 73.12 | 64.65 | 81.20 | 53.12 |
| Mem0g | 68.44 | 65.71 | 47.19 | 58.13 | 75.71 |
| GraphRAG | 67.60 | 79.55 | 54.96 | 50.16 | 58.33 |
| Mem0 | 66.88 | 67.13 | 51.15 | 55.51 | 72.93 |
| Zep | 65.99 | 61.70 | 41.35 | 49.31 | 76.60 |
| LangMem | 58.10 | 62.23 | 47.92 | 23.43 | 71.12 |
| MemU | 56.55 | 66.34 | 63.12 | 27.10 | 50.01 |
| OpenAI | 52.90 | 63.79 | 42.92 | 21.71 | 62.29 |
| A-Mem | 48.38 | 39.79 | 18.85 | 49.91 | 54.05 |
Dataset Characteristics
The LoCoMo paper describes an original dataset with 50 very long conversations. The official repository's current evaluation file, locomo10.json, is a 10-conversation subset selected for longer conversations and higher-quality annotations. This subset contains 272 sessions, 5,882 dialogue turns, and 1,986 QA annotations, averaging about 27.2 sessions and 588.2 turns per conversation.
LoCoMo is not only a test of whether a system can find one exact sentence. Its conversations are built around personas, timelines, event relations, and image references, and require the model to answer questions, summarize events, or continue multimodal dialogue across days and topics. For a Memory system such as GUMem, it mainly tests three capabilities: whether the system can recall correct facts from long histories, combine clues across sessions, and handle temporal order, causal relations, and unanswerable questions.
| Question type | Count | Main evaluation point |
|---|---|---|
| Single-hop | 841 | Recall an explicit fact from one context fragment. |
| Multi-hop | 282 | Combine multiple dialogue fragments or facts before answering. |
| Temporal | 321 | Understand dates, order, intervals, and event timing. |
| Open-domain | 96 | Infer an answer from conversation facts and commonsense knowledge. |
| Adversarial | 446 | Detect missing premises and avoid fabricating unsupported answers. |
This GUMem LoCoMo experiment excludes category=5 Adversarial questions and scores only the first four categories, or 1,540 questions, matching the Mem0 LoCoMo reporting scope.
GUMem vs Mem0
From the perspective of authority and accuracy, Mem0 is one of the most widely used Agent Memory products, so it can serve as a baseline for comparing memory recall quality and context cost. Compared with Mem0 New (2026.4), GUMem uses less than half the average context tokens in this LoCoMo evaluation while reaching a 92.9% overall Judge pass rate, higher than Mem0 New's 91.6%. This shows that GUMem can substantially reduce input context while maintaining higher overall answer correctness.
Experiment Details
Next Step
Read Query Memory to understand how recall settings affect latency and result quality.