Benchmark评估
LoCoMo
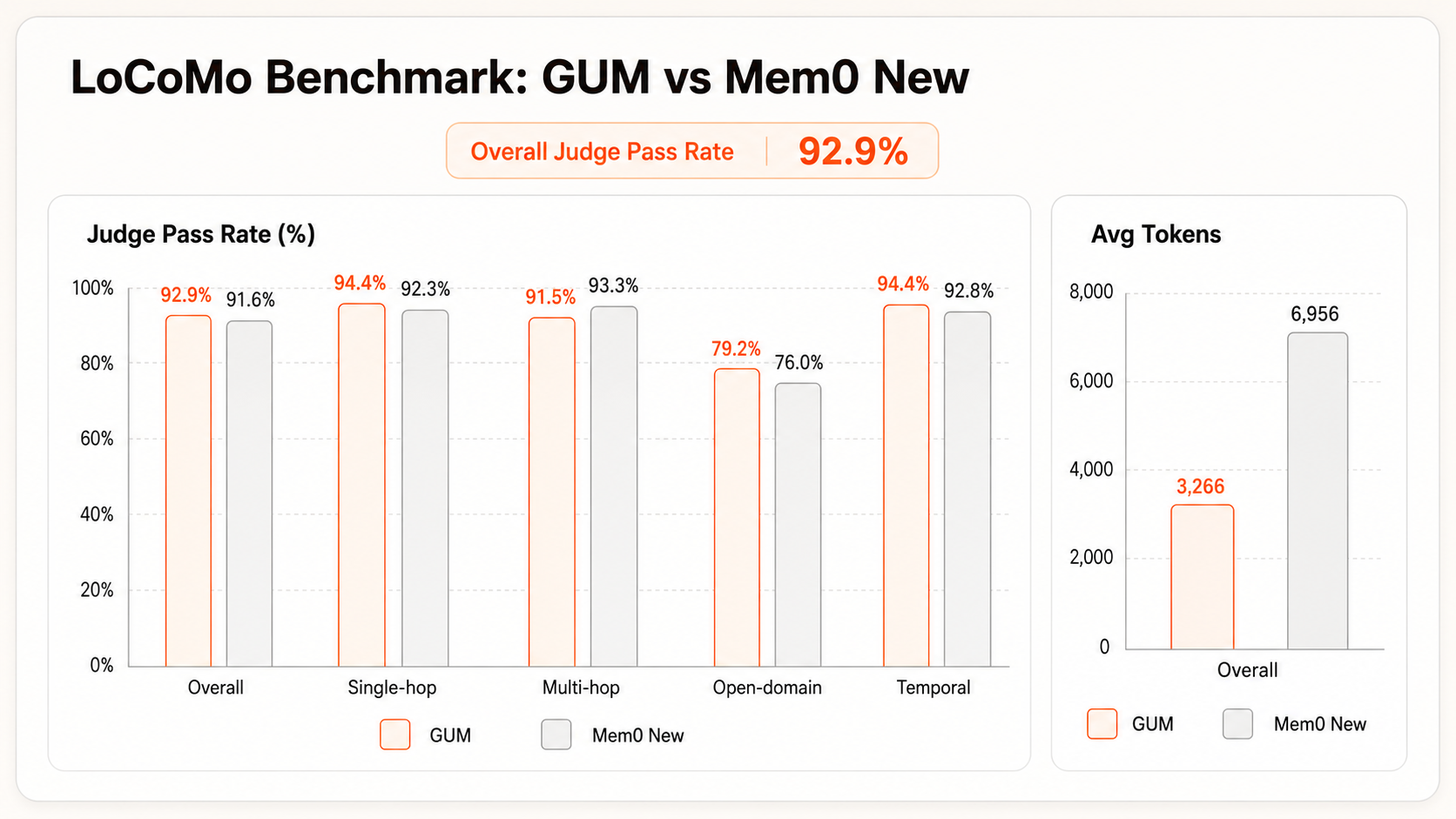
LoCoMo是长对话记忆评估中常用的benchmark,覆盖跨轮次、跨主题和时间相关问题,适合检验 Agent 能否从较长历史中召回稳定的用户事实和事件。GUMem能够实现92.9%的准确率,是目前的SOTA水平。
| 产品 | Overall | Single-hop | Multi-hop | Temporal | Open-domain |
|---|---|---|---|---|---|
| GUMem | 92.90 | 94.40 | 91.50 | 94.40 | 79.20 |
| Mem0 New April 2026 | 91.60 | 92.30 | 93.30 | 92.80 | 76.00 |
| HyperGraphRAG | 86.49 | 90.61 | 80.85 | 85.36 | 70.83 |
| MIRIX | 85.38 | 85.11 | 83.70 | 88.39 | 65.62 |
| HippoRAG 2 | 81.62 | 86.44 | 75.89 | 78.50 | 66.67 |
| LightRAG | 79.87 | 86.68 | 84.04 | 60.75 | 71.88 |
| MemOS | 75.80 | 81.09 | 67.49 | 75.18 | 55.90 |
| Membase | 72.01 | 73.12 | 64.65 | 81.20 | 53.12 |
| Mem0g | 68.44 | 65.71 | 47.19 | 58.13 | 75.71 |
| GraphRAG | 67.60 | 79.55 | 54.96 | 50.16 | 58.33 |
| Mem0 | 66.88 | 67.13 | 51.15 | 55.51 | 72.93 |
| Zep | 65.99 | 61.70 | 41.35 | 49.31 | 76.60 |
| LangMem | 58.10 | 62.23 | 47.92 | 23.43 | 71.12 |
| MemU | 56.55 | 66.34 | 63.12 | 27.10 | 50.01 |
| OpenAI | 52.90 | 63.79 | 42.92 | 21.71 | 62.29 |
| A-Mem | 48.38 | 39.79 | 18.85 | 49.91 | 54.05 |
数据集特点
LoCoMo中的原始数据集包含 50 条超长对话;官方仓库当前用于评测的 locomo10.json 是其中保留长对话和高质量标注后的 10 条对话子集。这个子集共包含 272 个 session、5,882 轮对话、1,986 个 QA 标注,平均每条对话约 27.2 个 session 和 588.2 轮。
LoCoMo 不只是检验“能否找到一句原文”。它把对话构造成带 persona、时间线、事件关系和图片引用的长期互动,并要求模型在多天、多主题的历史中回答问题、总结事件或继续生成多模态对话。对 GUMem 这类 Memory 系统来说,它主要考察三类能力:能否从长期历史中召回正确事实,能否把跨 session 的线索组合起来,能否处理时间顺序、因果关系和无法回答的问题。
| 题型 | 数量 | 主要考察点 |
|---|---|---|
| Single-hop | 841 | 从单个上下文片段召回明确事实。 |
| Multi-hop | 282 | 综合多个对话片段或多个事实后回答。 |
| Temporal | 321 | 理解日期、先后顺序、时间间隔和事件发生时间。 |
| Open-domain | 96 | 结合对话事实和常识推断答案。 |
| Adversarial | 446 | 判断问题前提是否缺失,避免编造不存在的答案。 |
本次 GUMem LoCoMo 实验排除了 category=5 的 Adversarial 题,只统计前四类 1,540 个问题,对齐 Mem0 的 LoCoMo 报告口径。
GUMem vs Mem0
从权威性和准确率角度出发,Mem0是目前最主流的Agent Memory产品之一,因此可以作为记忆召回效果和上下文成本的对比基线。与Mem0最新(2026.4)的测试结果比较而言:在本次 LoCoMo 评估中,GUMem 的平均上下文 token 低于 Mem0 New 的一半情况下,整体 Judge 通过率达到 92.9%,高于 Mem0 New 的 91.6%。这说明 GUMem 在显著减少输入上下文的同时,仍能保持更高的整体答案正确率。
实验细节
下一步
阅读 查询记忆 了解召回参数如何影响延迟和结果质量。