Memory 如何形成
新页面
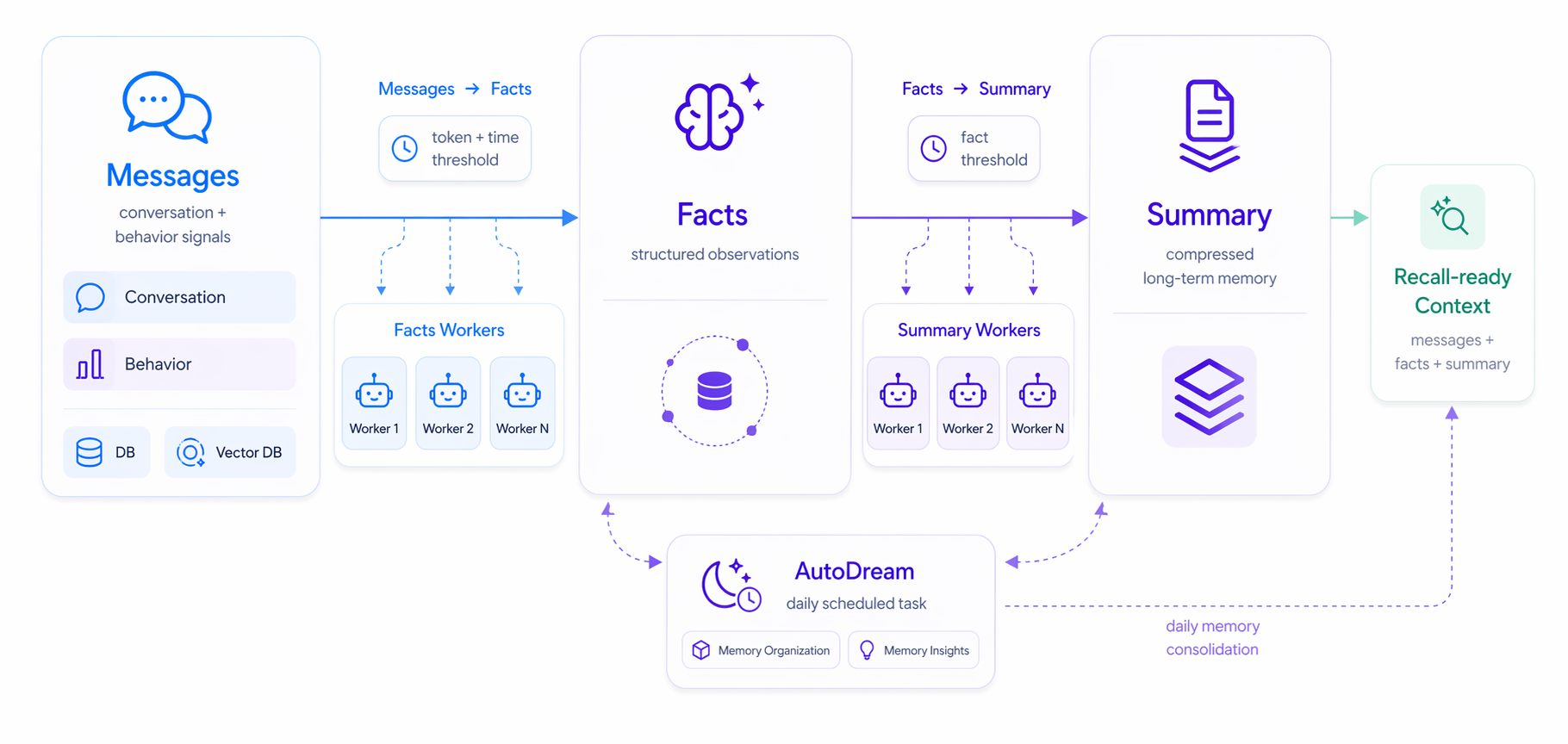
| 层级 | 作用 | 说明 |
|---|---|---|
Message | 原始输入 | 来自对话消息、搜索、筛选、收藏、工具调用或业务事件。Message 保留原始上下文,但本身不等于最终可复用的 Memory。 |
Facts | 可追踪事实 | 从 Message 中提取出的事实、偏好、约束、计划、身份、行为模式或时间线索。Facts 是解释和审计的证据层。 |
Summary | 长期记忆摘要 | 由一组 Facts 支撑的压缩记忆,适合在后续任务中直接召回。 |
Topic | 召回入口 | 用于把相关 Summary 组织到同一主题下,帮助 Query Memory 先定位记忆区域。 |
1. Message:原始输入
Message 记录用户和 Agent 在会话中说了什么,也可以记录用户和 Agent 在产品里做了什么。对话消息和行为事件共同构成 Memory 的原始输入层。
仅依赖对话容易遗漏行为意图。例如用户没有明确说“我偏好浅色跑鞋”,但连续筛选、停留和收藏行为可能已经表达了这个偏好。行为 Message 用来补齐这些隐含信号,让 GUMem 可以从产品使用过程中识别稳定模式。
主要字段:
| 字段 | 说明 |
|---|---|
role | 消息角色,例如 user、assistant、system。 |
content | 原始消息正文或行为描述。 |
timestamp | 消息或行为发生时间。 |
event_type | 行为类型,例如 search、click、filter、tool_call。 |
page | 行为发生的页面、场景或业务模块。 |
metadata | 业务自定义信息,例如来源、标签、设备或客户端信息。 |
2. Facts:可追踪事实
Facts 是从 Message 中抽取出的可复用信息单元。它们应该短、具体、可追踪,并且只表达输入中有依据的信息。
Facts 的价值在于把原始噪声转成可检索、可引用、可更新的 Memory。相比完整消息或点击流,Facts 更适合用于解释为什么 Agent 记住了某件事,也更适合在用户更正或删除时定位来源。
一个 Message 可能生成多个 Facts。例如用户说“欧洲团队默认 Berlin,美洲团队默认 Toronto,但周五不要安排会议”,GUMem 可以把城市偏好和周五限制拆成不同 Facts。紧密绑定的信息不会被硬拆,例如“欧洲团队默认 Berlin”应保持在同一条事实里。
主要字段:
| 字段 | 说明 |
|---|---|
content | 抽取出的事实、偏好、约束、长期目标或行为模式。 |
entities | 识别出的实体列表。 |
source_message_ids | 支撑该 Fact 的原始 message ID 列表。 |
labels | 用于分类或检索的标签。 |
status | 处理状态,例如 pending、chunked、processed、failed。 |
time_range | Fact 覆盖的时间范围。 |
created_at | Fact 创建时间。 |
3. Summary:长期记忆摘要
Summary 用来把一段消息、行为记录或一组 Facts 压缩成更稳定的阶段性上下文。它解决的是上下文过长、行为信号分散和重复信息过多的问题。
Summary 不替代 Facts。Facts 保留单条可引用证据,Summary 把一组 Facts 支撑的信息压缩成可检索、可治理的长期记忆。例如一次购物过程中的预算、尺码、使用场景和外观偏好,可以形成一个更容易召回的购物意图 Summary。
主要字段:
| 字段 | 说明 |
|---|---|
content | 由 Facts 支撑的长期记忆内容,也是召回时最核心的文本。 |
topic | 高层主题标签,用于把 Summary 归入同一业务语义或用户画像维度。 |
source_facts | 直接支撑该 Summary 的 Facts。 |
confidence | Summary 级别的置信度,范围为 0.0 到 1.0。 |
time | 事件时间信息,包含 event_start 和 event_end。 |
labels | 标签或分类,用于保留画像范围、业务分类或检索条件。 |
entities | 与该 Summary 明确关联的命名实体。 |
decay_factor | 记忆重要性随时间衰减的速率。 |
validity | 有效性状态,例如 active、invalid、deprecated。 |
memory_status | 记忆管理状态,例如 active、deprioritized、archived、deleted。 |
retrieval_boost | 检索排序加权因子。 |
evidence | 支撑该 Summary 的证据,例如来源 Facts、行为日志或锚点。 |
anchors | 关键引用点,例如订单 ID、预约 ID 或其他业务对象标识。 |
4. Topic:召回入口
Topic 是 Summary 的高层组织方式。它不是给用户展示的目录,而是 Query Memory 找回长期记忆时的第一层入口。
当 Agent 需要生成下一轮响应时,GUMem 会根据当前 query 先找到相关 Topic,再取回 Topic 下的 Summary。如果 Summary 不足以回答当前问题,GUMem 会继续补充支撑它的 Facts 和近期 Message。
这个上下文不要求包含所有历史信息。它只保留当前任务需要的关键信号,让 Agent 在生成回复、推荐、执行工具或做风险判断时拥有足够背景。
主要字段:
| 字段 | 说明 |
|---|---|
query | 当前任务或用户问题。 |
short_term_context | 最近会话消息组成的短期上下文。 |
mid_term_context | 与 query 相关的中期记忆片段。 |
long_term_user_context | 跨 Session 复用的用户长期记忆。 |
formatted_context | 已格式化的最终上下文,通常可直接放入 Agent prompt。 |
失败和边界
- 不要把 Summary 当成不可更改的真相。用户后续更正信息时,应写入新的 Message,让 GUMem 形成新的 Facts 和 Summary。
- 不要依赖 GUMem 保存所有原始输入。只写入未来会影响回答、推荐、工具调用或风险判断的信息。
- 不要把未确认推断写成 Facts。用户没有明确表达或行为没有足够证据时,应保留不确定性。
- 不要用 GUMem 替代业务数据库。订单、权限、账单、库存等强一致数据仍应由业务系统负责。
示例:电商购物记忆
这个示例展示 GUMem 如何在电商导购场景中,同时利用对话消息和行为日志形成 Memory,并在下一次对话中召回。
1. 原始输入
对话消息
用户:想买一双日常慢跑鞋,不要太硬,预算 800 以内。
用户:我主要在公园跑,单次大概 5 公里,最好别太夸张。行为日志
筛选:品类 = 跑鞋
筛选:价格 = 500-800
筛选:尺码 = 42
浏览:4 双缓震跑鞋
收藏:2 双浅色鞋款
停留:包含“脚感柔软”和“日常训练”的评价
跳过:碳板竞速鞋2. 生成 Facts
- 用户正在寻找日常慢跑鞋。
- 用户预算大多在 800 以内。
- 用户常看 42 码。
- 用户偏好缓震、脚感不硬的跑鞋。
- 用户更关注公园 5 公里慢跑场景。
- 用户对浅色、外观不夸张的鞋款更感兴趣。
- 用户当前不倾向碳板竞速鞋。
3. 生成 Summary
该用户近期有购买日常慢跑鞋的意图,主要使用场景是公园 5 公里慢跑,偏好舒适缓震、浅色低调外观和 800 元以内的价格区间,尺码大概率为 42。
4. 归入 Topic
Topic: running shoes5. 对话中召回
用户:昨天看的鞋还有推荐吗?
Agent:可以。基于你昨天主要浏览和收藏的鞋款,我会优先推荐 500-800 元、42 码有货、适合日常慢跑的缓震跑鞋,并避开偏竞速的碳板鞋。你更想要脚感更软一点,还是鞋身更轻一点?这段对话里,42 码、500-800 元、浅色低调、避开碳板竞速鞋 并不完全来自用户显式表达,而是由筛选、浏览、收藏、停留和跳过等行为信息补全。
下一步
- 阅读 Quick Start 查看 GUMem 的最短接入路径。
- 阅读 SDK 查看当前 SDK 的范围和接口状态。
- 阅读 User Case 了解这些概念在典型场景中的使用方式。